How It's Made
How Hundreds of Retailers Use the Instacart Partner Platform to Drive In-Store Efficiencies
Authors: Benjamin S. Knight & Bryan Rusk
One of our core missions at Instacart is to enable our retailer partners. When we succeed at deriving efficient delivery routes, accurately predicting the time it takes to fulfill an order, or estimating the amount of personnel required to staff a store on a given day, retailers are able to fulfill more orders, faster, at lower cost.
Problems of the kind above are generally receptive to machine learning (ML) and other optimization strategies (e.g. TSP algorithms). However, these solutions might not always represent a good fit for all retailers. A given store may have relatively low volume of orders, which can pose challenges for data-hungry ML algorithms. Alternatively, the underlying problem space might not be well-defined as a consequence of continuous efforts to drive innovation.
Like Instacart, our retailer partners are committed to exploring new ways of making fulfillment faster and easier. Routing the shopper through the store efficiently is one of our most powerful levers for unlocking faster picking. To that end, we need to present item location data to shoppers that is formatted and sorted in such a way as to make the shopping list as helpful as possible.
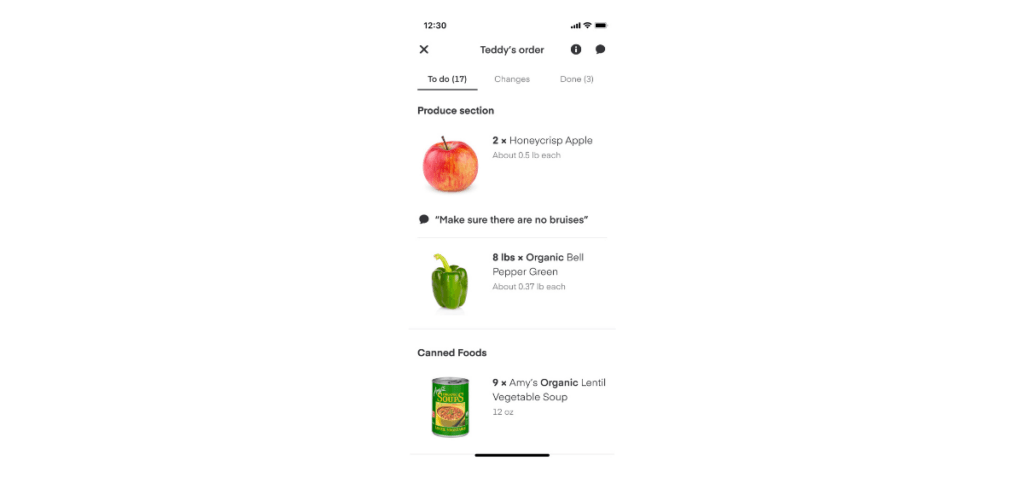
What kind of item location data is most useful? We already show the aisle, but what about the shelf? At any point in time, there might be multiple experiments running designed to test new store layouts and item location data formats.
At the same time, even the most detailed item location information will underperform unless the shopping list is sorted efficiently. A poorly sorted shopping list can lead to shoppers retracing their steps, which costs precious time.
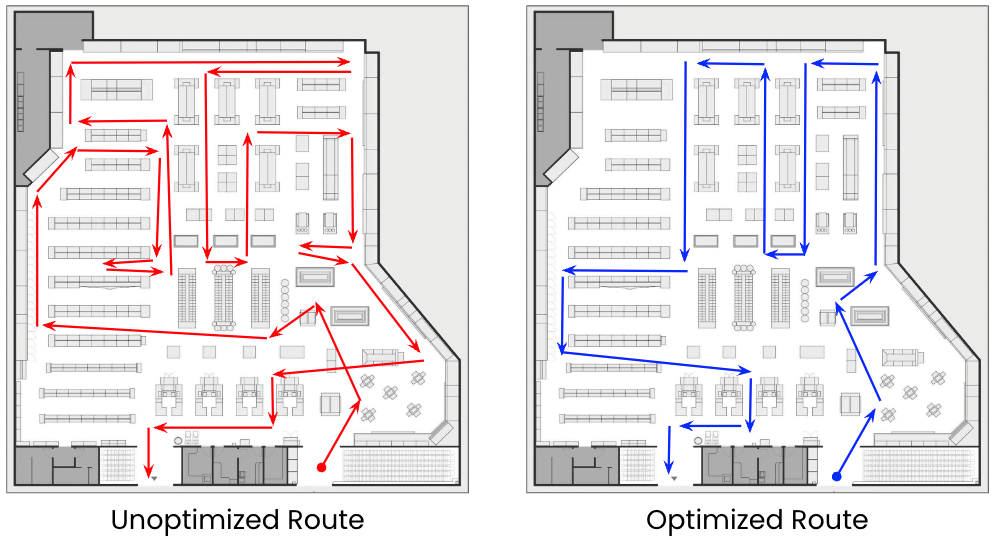
Here is where things get complicated. Conventional item location data exists in a hierarchical relationship of mixed data types, including integers (‘Aisle 1’) and strings (e.g. ‘Produce Department’).

Unpacking this data and creating efficient sorts from it is a complicated task involving multiple heuristics and algorithms. The cost associated with building and maintaining the associated pipelines is not trivial. Taken alongside constant experimentation with new data types, formats, and store layouts, we reach a point where any pipeline designed to create an efficiently sorted shopping list is likely to have a short shelf life. In such a world, how does one best deploy scarce data science and data engineering resources?
Optimizing for the Here and Now: Creating an Efficiently-Sorted Shopping List
We need a solution to the shopping list sorting problem that drives efficiency, but is also adaptable. To this end, we settled on a portfolio of solutions. On the one hand, we need a default method of sequencing item location data that can assume a wide variety of formats (e.g. {aisle: 1, shelf: 2} versus {department : seafood, aisle : 10A}. On the other hand, we need a mechanism for responding quickly to changes to the underlying data (e.g. the retailer adds a new “shelf number” attribute) without necessarily scrapping everything that has been built to date.
Our default method of sequencing item location data needs to be grounded in logic that can accommodate a variety of data types and sources. For example, some retailers may not even share item location data, necessitating that we sort using product categories as opposed to catalog data. To this end we turn to product taxonomy data, as it offers a framework that is suitably abstract, robust, and scalable.
While product category data is extensible, we lack precise information regarding where within the store the product resides. To estimate this, we measure the amount of time elapsed between when certain products were acquired by an Instacart shopper. We can combine data across many shoppers by taking a weighted average. For instance, if shopper A picked an item from produce, texted a customer, and then picked an item from bulk goods, then we know that the amount of time elapsed between produce and bulk goods is not entirely reflective of the real-world distance traveled. That particular data point would be down-weighted accordingly.
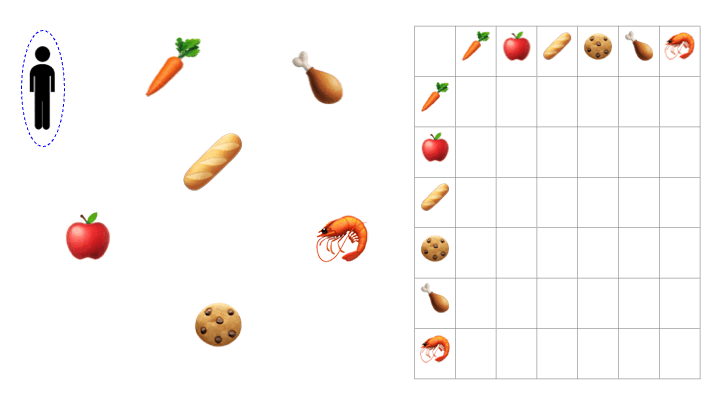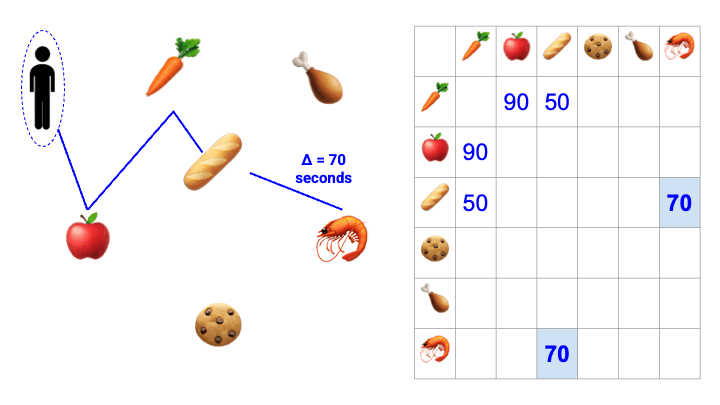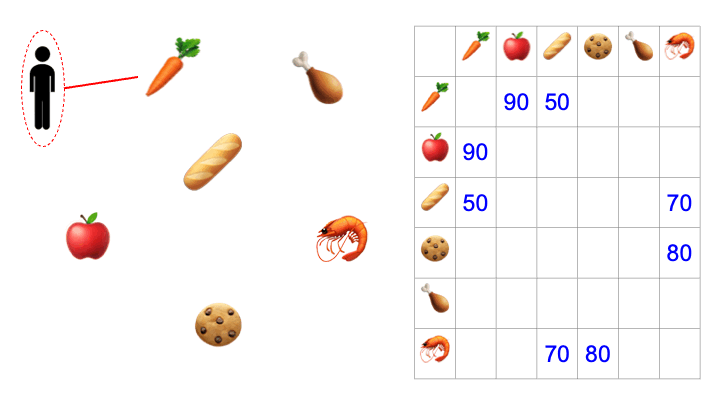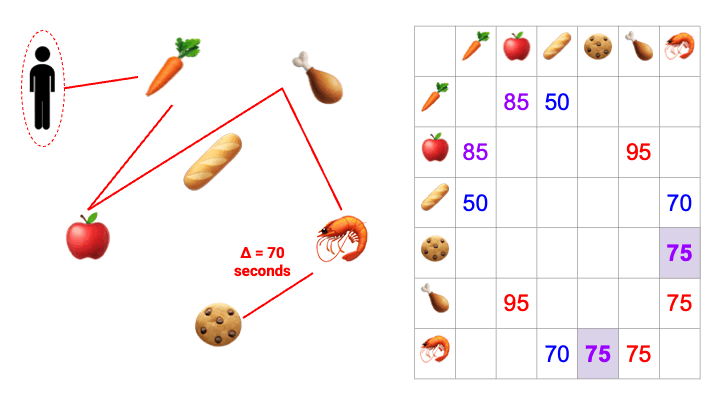
The resulting distance matrix is our “source of truth,” and is routinely updated. When the time comes to create a shopping list, we iterate through the distance matrix, proceeding from one product category to the next so as to minimize the distance between steps. If an order contains carrots, cookies, and chicken then we query this subset of items from the resulting sequence, and voilà — we have our sorted shopping list.

Optimizing for the Future: When Tools Are More Robust Than Solutions
Using the approach shown above, Instacart has a solution for sorting any shopping list, regardless of the available data. However, our goal is not just to fulfill orders faster, but to enable retailers to innovate on their own accord. To that end, we need a versatile platform that offers not just solutions, but tools to iterate and innovate on those solutions. Enter: Instacart’s Platform Portal (IPP).
Imagine that a store decides to offer a new line of pre-made soups, salads, and sandwiches, and that the manager of this store wants the shopping lists to reflect that this new section is after the baked goods section, but before the deli section. In one scenario, the store manager reaches out to corporate HQ, which then pings Instacart HQ, which then designates the appropriate product team, which ultimately creates a ticket for an engineer to implement an update. In a different scenario, the store manager logs into Instacart’s Instacart Platform Portal, enters the updated information via a convenient GUI, and the update automatically deploys. In this second scenario, retailers can experiment with reformatting or reordering their data and observe the impact almost immediately — no engineering effort required.

To build such a tool, we need a dataset of default templates and sequences. By ‘template,’ we are referring to a data format of the kind shown in Figure 1 (e.g. Aisle : 1 or Department : Seafood, Shelf : 14). While a template encodes the structure of the data, a ‘sequence’ encodes the order with which it needs to be presented to the shopper. The most up-to-date data provided by the retailer is secured in a dedicated table (RetailerLocationData). A cron job ensures that updates are promulgated to the tables storing the appropriate templates (AisleTemplates) and default sequences (SortedAisles).
Now, let’s say that our store manager wants to edit the default configuration in order to add the aforementioned pre-made soups, salads, and sandwiches. In step 1 of Figure 4, the store manager logins into the partner portal, selects the relevant store location(s), edits the corresponding catalog entities, and saves the changes (see below).

With the changes committed (step 2) and the new data written (step 3) an update goes out to SortedAisles. Older, out-of-date sequences are then deprecated in favor of the latest update (step 4). With AisleTemplates and SortedAisles both in sync with one another as well as with the latest catalog data residing in RetailerLocationData, a success code goes out to the Shopper app (step 5), confirming that all assets are up-to-date and are ready to generate shopping lists in accordance with the store manager’s latest instructions.
Conclusion
Creating an efficient shopping list is a problem ripe for conventional optimization techniques and machine learning — methods which Instacart has years of experience using and iterating on. However, Instacart supports over 900 retail partners across tens of thousands of store locations — stores that can vary in their order volume by orders of magnitude. No single optimized solution, no matter how sophisticated, will be able to serve such a diverse set of needs perfectly. When we take into account evolving product selections and innovations in store layout and catalog data, the need for a portfolio of tools becomes apparent.
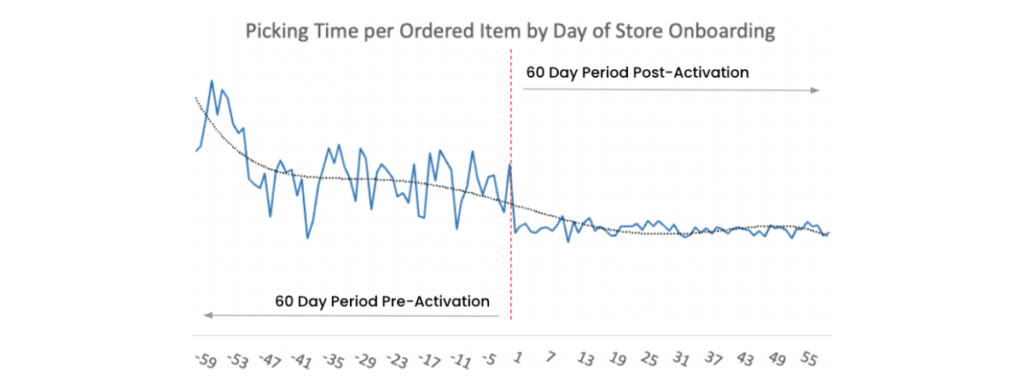
While this new functionality is still in the early stages of adoption, initial trends suggest positive impact in the form of reduced pick times. Most importantly, store managers are able to experiment and iterate quickly without the need to implement new code.
A good set of tools can be more robust than specific solutions, and to be the best partner that we can be (whether to our shoppers or our retailer partners) Instacart needs to provide both. By adding the capacity for manual sorting to our ‘toolbox,’ Instacart can simultaneously empower innovation while continuing to optimize solutions grounded in ML.
Acknowledgements
An idea is only ever as good as its execution, and we want to give sincere thanks to all those who worked to turn an image on a whiteboard into a real-world capability. Our leaders from the Product (Jennie Braunstein) and Pickup (Charles Strickland) teams kept us on schedule, and ensured that the problems we tackled were productive ones. From our Partners team, we are indebted to Latrice Coleman and Kelly Bastyr, who worked with retailers to onboard them to the new tool with increasing enthusiasm. Our designers, Andressa Bougleux and Dario Fidanza, grappled with the difficult problem of rendering complicated item location data in an accessible manner. Lastly, hats off to the engineers who made all of this possible. Thank you Collin Yen, Darren Johnson, Dan Nguyen, Kangning Hu, Rock Hu, Qi Xi, and Zhenghao He for your hard work and dedication.
Instacart
Instacart is the leading grocery technology company in North America, partnering with more than 1,400 national, regional, and local retail banners to deliver from more than 80,000 stores across more than 14,000 cities in North America. To read more Instacart posts, you can browse the company blog or search by keyword using the search bar at the top of the page. Building a Data-Driven company with Anahita Tafvizi, Instacart’s Vice President and Head of Data Science
Building a Data-Driven company with Anahita Tafvizi, Instacart’s Vice President and Head of Data Science 

Most Recent in How It's Made

How It's Made
One Model to Serve Them All: How Instacart deployed a single Deep Learning pCTR model for multiple surfaces with improved operations and performance along the way
Authors: Cheng Jia, Peng Qi, Joseph Haraldson, Adway Dhillon, Qiao Jiang, Sharath Rao Introduction Instacart Ads and Ranking Models At Instacart Ads, our focus lies in delivering the utmost relevance in advertisements to our customers, facilitating novel product discovery and enhancing…...
Dec 19, 2023
How It's Made
Monte Carlo, Puppetry and Laughter: The Unexpected Joys of Prompt Engineering
Author: Ben Bader The universe of the current Large Language Models (LLMs) engineering is electrifying, to say the least. The industry has been on fire with change since the launch of ChatGPT in November of…...
Dec 19, 2023
How It's Made
Unveiling the Core of Instacart’s Griffin 2.0: A Deep Dive into the Machine Learning Training Platform
Authors: Han Li, Sahil Khanna, Jocelyn De La Rosa, Moping Dou, Sharad Gupta, Chenyang Yu and Rajpal Paryani Background About a year ago, we introduced the first version of Griffin, Instacart’s first ML Platform, detailing its development and support for end-to-end ML in…...
Nov 22, 2023