How It's Made
How Instacart Uses Embeddings to Improve Search Relevance

Authors: Xiao Xiao, Taesik Na, Tejaswi Tenneti, Guanghua Shu
As a fast-growing e-commerce platform and the leading grocery technology company, Instacart has an ever-expanding catalog of over 1 billion products from 900+ retailers, spanning a variety of categories from traditional grocery to beauty, pets, alcohol, home improvement items, electronics and more. Providing a smooth search experience is essential to ensure that our customers can find the products they love with ease, so that they have more time to enjoy them.
At Instacart, we strive to create a search experience that presents our customers with highly relevant products catered to their personal preferences with low latency. This is achieved by a collection of machine learning models that identify the intent of customers’ search queries, retrieve the most relevant products from the catalog, and rank them in such a way that balances product relevance with popularity and each customer’s personal preference.
Identifying which products are relevant for a given search query isn’t an easy task, especially given the diversity of search queries and the large number of products on Instacart’s platform. Search queries on Instacart follow a highly skewed distribution with <1000 popular queries accounting for >50% of search traffic and a very long tail of other queries, and they can range from being highly specific (e.g., “Buffalo Wild Wings parmesan garlic sauce”) to very broad (e.g., “appetizers”). While we can leverage past user engagement and category/brand/text matching for queries that are popular or specific, a more holistic understanding is required to gauge the relevance between the large number of queries and products when these signals are sparse.
In this blog post, we will introduce ITEMS (the Instacart Transformer-based Embedding Model for Search), a deep learning model that fills in the gap by creating a dense, unified representation of search queries and products. By jointly learning the representation of queries, products, and their relationships, ITEMS is able to provide a reliable measure of relevance for any query and product combinations even when customer engagement or categorical signals are missing or misleading. Here we will give a high-level overview of the model, discuss our learnings in model training and deployment, and showcase how the adoption of ITEMS has led to a significant improvement in search as well as other surfaces at Instacart.
ITEMS Model Architecture
ITEMS takes search queries and product information as inputs, and projects them into the same vector space so that queries and products can be directly compared against each other for relevance. This is achieved by a Sentence Transformers model with two towers (i.e., the bi-encoder architecture), where each tower is a transformer-based module. The two-tower model allows search queries and products to be encoded independently, with queries going through one tower and products going through another. This design has the benefit of retaining the autonomy between the two towers, where the vector representation (embedding) for a product does not change regardless of which query it is being compared with, and vice versa. Once the model is trained, query embeddings and product embeddings can be separately computed, stored, and retrieved during runtime. Such flexibility and efficiency makes the two-tower model a popular choice for retrieval and ranking among e-commerce.

Training ITEMS with Instacart Search Impression Data
We initialized the two towers in ITEMS with pretrained weights from the Sentence Transformers repository, and fine-tuned the model with Instacart’s in-house datasets. To learn the relationship between queries and products, the model requires both positive and negative (query, product) pairs, where the two are relevant (e.g., “milk” <-> Guida’s Dairy Whole Milk) or irrelevant (e.g., “toilet paper” <-> Dixie Everyday Dinner Paper Plates). Through fine-tuning, the model learns to encode relevant query and product so that the vectors are close to each other in the embedding space, while vectors from irrelevant pairs are far apart.
The positive (query, product) pairs were mined from Instacart’s search log, where a customer issued a search query and converted on a product by adding it to their cart. While this signal isn’t perfect, we have found a pretty high correlation between product conversion and its relevance to the search query. In the next section, we will talk about how to further improve the quality of the positive training examples. On the other hand, the opposite isn’t necessarily true — there could be a variety of reasons why a customer didn’t convert on a product; and personal preference on brand, flavor and nutritional values often plays a big role. As a result we cannot naively use unconverted products as a negative example for a search query.
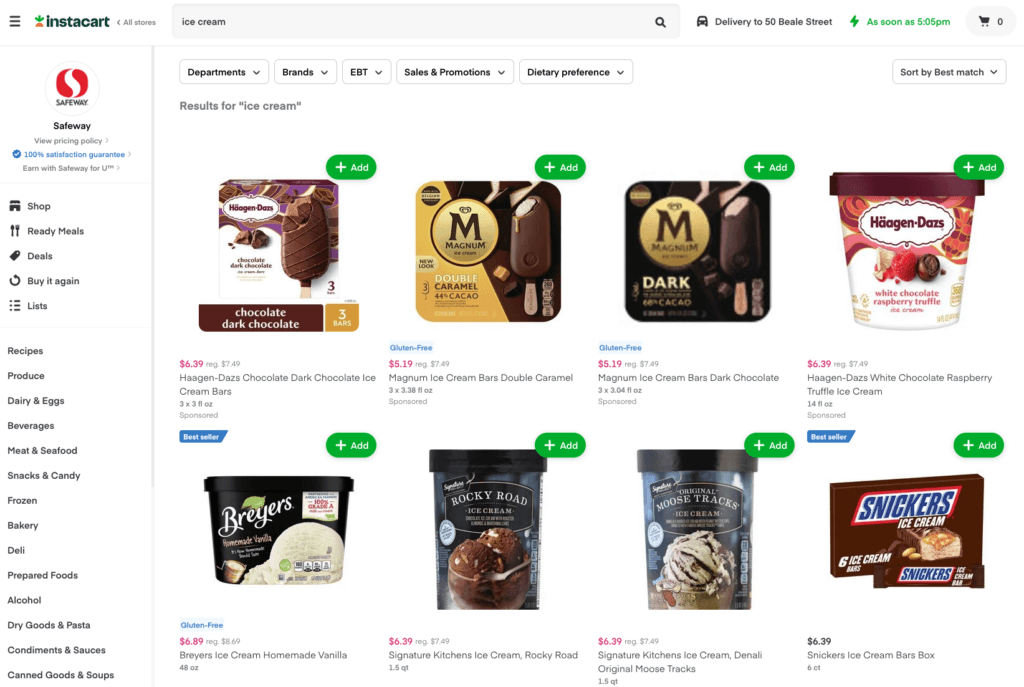
We solved this problem by using an in-batch negative approach. Given a batch of positive training data (query₁, product₁), (query₂, product₂), …, all off-diagonal (queryᵢ, productⱼ) pairs where i != j are assumed to be irrelevant (Figure 3). This allows the model to learn to distinguish relevant products from irrelevant products for a given query, without explicitly providing negative examples which are hard to mine. To make training more challenging, we applied self-adversarial re-weighting (Figure 3, right) during training, where the in-batch negative examples are given different weights as a function of the model’s prediction. (query, product) pairs that are easy for the model to identify as being irrelevant (e.g., “tortilla” <-> large coffee mug) are given a lower weight, whereas hard examples that the model struggles with (e.g., “tortilla” <-> Tostitos tortilla chips) are given a higher weight. This approach helps the model focus on the hard examples and learn to better capture the nuances.

Data Augmentation and Multi-Task Learning
The product catalog at Instacart is a rich data source with metadata for most products on our platform, including category, brand, size, price, images, dietary and nutritional information etc. We take advantage of this information to augment ITEMS in three ways.
- Expansion of product input: Instead of using only the name of the product as input to ITEMS, we expanded it by concatenating the other product information to provide a richer context. For example, product “Organic 2% Reduced Fat Milk” is augmented to “[PN] Organic 2% Reduced Fat Milk [PBN] GreenWise [PCS] Milk [PAS] organic, kosher, gluten free”, where tokens in brackets (such as “[PN]” and “[PBN]”) are special tokens to help the model segment the input properly.
- Synthetic positive training data: Due to the size of the catalog and the highly skewed distribution of product popularity, some products have no historical conversions and therefore are not included in the training data for ITEMS. To increase the coverage of these rarer products, we created synthetic queries by permuting the various product attributes. For example, the product “Organic 2% Reduced Fat Milk” is from the brand “GreenWise”, belongs to the category “Milk”, and is 1 gal in size. These attributes can be mixed and matched to create the following synthetic queries:
- “GreenWise”
- “GreenWise Organic 2% Reduced Fat Milk”
- “Milk 1 gal”
- …
The synthetic queries and their corresponding products form positive training examples, and are combined with organic examples from search impression data for training. The percentage of the synthetic data is kept very low to ensure that it doesn’t introduce bias by overwhelming the organic examples.
- Multi-task learning: In addition to the main objective of ITEMS, which is to identify the relevance between queries and products, we added auxiliary training tasks to the product tower by using product metadata. Given a product, the model not only learns its representation, but also tries to predict its brand as well as the categories that it belongs to. This multi-task learning regime stabilizes model training, and ensures that products belonging to the same category or brand are clustered in the vector space.
Data Quantity VS Data Quality
While conversion– when a customer adds a product to their cart after having searched for it– is usually a good indicator of relevance between the query and the product, e-commerce search logs are intrinsically noisy. At Instacart, consumers often add multiple items to cart to build their shopping basket, similar to a real-life grocery shopping experience. An item can be added to cart even when it is not relevant to the search query as long as it is something that the customer needs — for example, a customer who searches for “cereal” may also happen to add milk to cart in the same search session as they prepare for breakfast. This would result in false positives if we are to retain all converted (query, product) pairs for model training. Contradicting the common knowledge that deep learning models (such as the one we use for ITEMS) are data hungry and usually benefit from a larger training dataset, we found that performance of ITEMS drops when the training dataset is expanded beyond a certain point where less reliable training examples introduce too much noise.
How can we strike a balance between data quantity and data quality? For a search query, if we rank the converted products by their conversion frequency, those products on top are likely to be highly relevant, while those further down are often “add-ons” that are irrelevant to the original intent of the query. We can then set a threshold to only keep those products that are most likely to be relevant. By adjusting this threshold, we were able to create training datasets of different sizes and varying degrees of reliability.

To get the best of both worlds (of quantity and quality), we further adopted a cascade training scheme. The model is first trained using a larger, noisier warmup dataset, where more converted products are retained for each query as positive examples; this is followed by a fine-tuning step with a smaller dataset of higher quality, where fewer products are retained with a higher conversion threshold. The two towers of ITEMS have shared parameters in the first training stage, which helps the model pick up commonalities between queries and products. In the fine-tuning stage, the parameters of the two towers are untied, allowing the model to attune to the unique characteristics of the two domains.
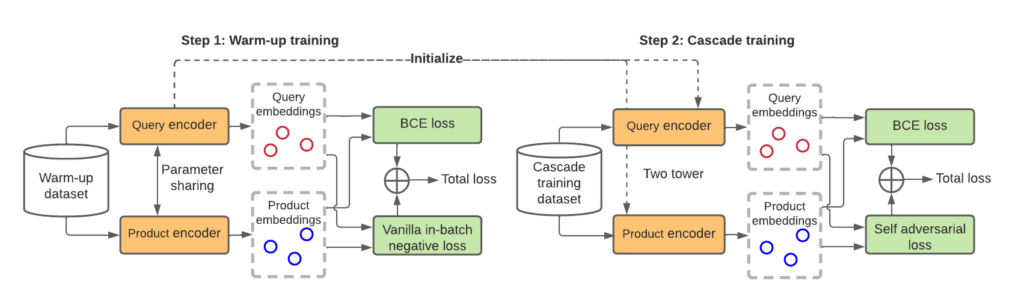
ITEMS in Action
Once the model is trained, the query and product embeddings from ITEMS are informative representations that capture their semantic relevance. Evaluation with a manually labeled dataset shows that the embedding score between queries and products is well correlated with human perception of what’s relevant. Though the model was trained using historical conversion data, the embedding score is more stable and much less prone to popularity bias compared with the raw clickthrough rate.
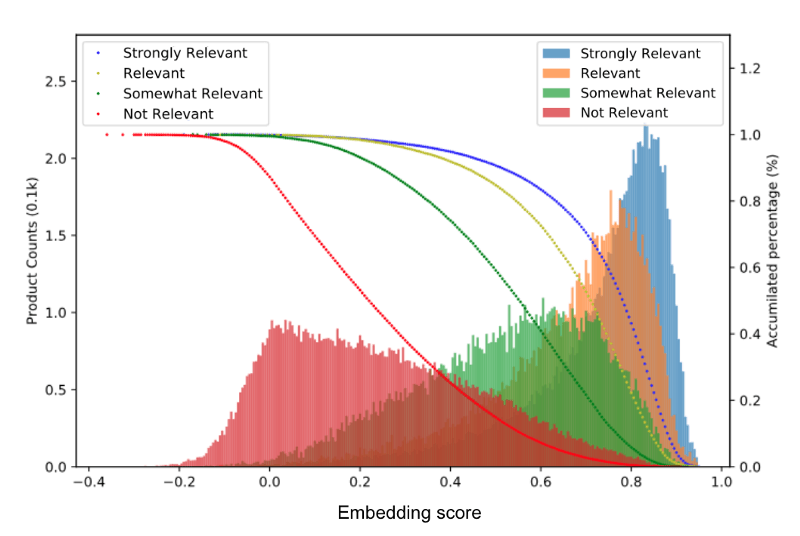

Training and deployment of ITEMS are facilitated by Instacart’s MLOps platform, Griffin. The model carries out daily offline scoring jobs that pre-computes the embeddings for new search queries and new products. The product embeddings are organized into indices using the FAISS library and served in an approximate nearest neighbor (ANN) service with daily updates to the indices, so that relevant products can be easily retrieved for incoming queries. For the query embeddings, we take a hybrid approach where the embedding for the vast majority (>95%) of the search queries are retrieved via FeatureStore lookup, and the few remaining ones not yet cached in FeatureStore are computed on the fly. This allows us to cover 100% of the search queries while maintaining a low latency (<8ms).

Improving Search Relevance
Since its launch, ITEMS has been an integral part of the search experience at Instacart. We use the embedding-based retrieval (EBR) system to retrieve the most relevant products for search queries from the ANN service based on their semantic similarity. Complementing the existing keyword-based and category-based retrieval, EBR is especially powerful for queries that are long or ambiguous. Once the products are retrieved, embedding score plays an important role as a feature in ranking functions, which balances multiple objectives including relevance, popularity, and personal preference, and surfaces products that best fits the customers’ needs.
Online A/B testing shows that ITEMS has led to +1.2% in mean reciprocal rank (MRR) of the first converted item in search, +4.1% in cart adds per search (CAPS), and a substantial increase in gross merchandise value (GMV).

Semantic Deduplication to Increase Diversity
While ITEMS provides a measure of relevance between queries and products as the cosine similarity between the two vectors, a similar approach can be extended to compute the similarity between two products or two queries. The latter is adopted by Autocomplete as a filter to remove suggestions that are too similar to one another (e.g., “fresh bananas” and “bananas fresh”, “applesauce” and “apple sauce”). Removing semantically identical suggestions improves the user experience by presenting to them a set of suggestions that are distinct, diverse, and are more likely to fit their needs.

Final Thoughts
With ITEMS we see the power of representation learning and deep retrieval in e-commerce. Its ability to capture the semantic meaning and the intent of search queries allows us to effectively surface the most relevant products to our customers, making their shopping experience more efficient with less friction. These topics are active areas of research, and we believe there is a lot more to ITEMS’ potential. By introducing additional signals and experimenting with state-of-the-art advancements in model architecture, we are working towards the next iteration of ITEMS that will be even more accurate, more context-aware, and carry richer information.
This work is published at SIGIR eCom 2022. If you’re interested in the implementation details, check out our paper here.
Acknowledgements to Zhihong Xu, Wideet Shende, Akshay Nair, Young Rao, Saurav Manchanda, and our previous PhD intern Yuqing Xie, who have contributed to ITEMS through multiple iterations.
Instacart
Author
Instacart is the leading grocery technology company in North America, partnering with more than 1,400 national, regional, and local retail banners to deliver from more than 80,000 stores across more than 14,000 cities in North America. To read more Instacart posts, you can browse the company blog or search by keyword using the search bar at the top of the page. “Avacado” or Avocado?
“Avacado” or Avocado?  7 steps to get started with large-scale labeling
7 steps to get started with large-scale labeling  How Instacart Uses Machine Learning-Driven Autocomplete to Help People Fill Their Carts
How Instacart Uses Machine Learning-Driven Autocomplete to Help People Fill Their Carts  Lessons Learned: The Journey to Real-Time Machine Learning at Instacart
Lessons Learned: The Journey to Real-Time Machine Learning at Instacart 

Most Recent in How It's Made

How It's Made
One Model to Serve Them All: How Instacart deployed a single Deep Learning pCTR model for multiple surfaces with improved operations and performance along the way
Authors: Cheng Jia, Peng Qi, Joseph Haraldson, Adway Dhillon, Qiao Jiang, Sharath Rao Introduction Instacart Ads and Ranking Models At Instacart Ads, our focus lies in delivering the utmost relevance in advertisements to our customers, facilitating novel product discovery and enhancing…...
Dec 19, 2023
How It's Made
Monte Carlo, Puppetry and Laughter: The Unexpected Joys of Prompt Engineering
Author: Ben Bader The universe of the current Large Language Models (LLMs) engineering is electrifying, to say the least. The industry has been on fire with change since the launch of ChatGPT in November of…...
Dec 19, 2023
How It's Made
Unveiling the Core of Instacart’s Griffin 2.0: A Deep Dive into the Machine Learning Training Platform
Authors: Han Li, Sahil Khanna, Jocelyn De La Rosa, Moping Dou, Sharad Gupta, Chenyang Yu and Rajpal Paryani Background About a year ago, we introduced the first version of Griffin, Instacart’s first ML Platform, detailing its development and support for end-to-end ML in…...
Nov 22, 2023