How It's Made
Lessons Learned: The Journey to Real-Time Machine Learning at Instacart

Authors: Guanghua Shu and Sahil Khanna
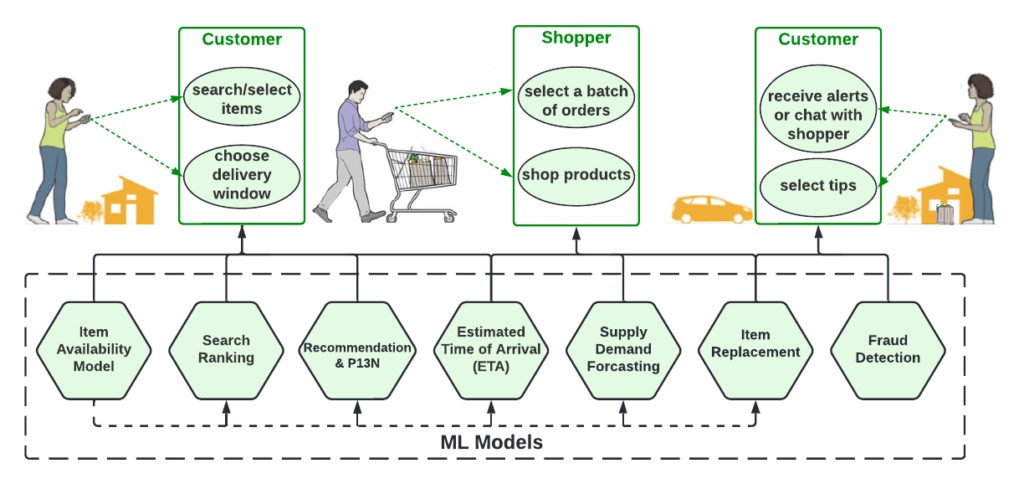
Instacart incorporates machine learning extensively to improve the quality of experience for all actors in our “four-sided marketplace” — customers who place orders on Instacart apps to get deliveries in as fast as 30 minutes, shoppers who can go online at anytime to fulfill customer orders, retailers that sell their products and can make updates to their catalog in real time, and the brand partners that participate in auctions on the Instacart Advertising platform to promote their products.
Figure 1 depicts a typical shopping journey at Instacart, powered by hundreds of machine learning models. All of these actions happen in real time, which means leveraging machine learning in real-time can provide significant value to the business. One of the major changes we have gone through is transitioning many of our batch-oriented ML systems into real-time. In this post, we describe our transition process, review main challenges and decisions, and draw important lessons that could help others learn from our experience.
History of Batch-Oriented ML Systems
Most machine learning in production is about leveraging signals (features) derived from raw data to predict targeted goals (labels). The quality of features is crucial and the features are largely categorized into two types by freshness:
- Batch features: Features extracted from historical data, often through batch processing. These types of features usually change infrequently, such as category or nutrition information of a food product.
- Real-time features: Features extracted from real-time data, often through stream processing. These types of features usually change frequently and the changes are essential for model prediction and decision-making. Some examples are real-time item availability, supply (number of online shoppers) and demand (number of orders), and customers real-time shopping sessions.
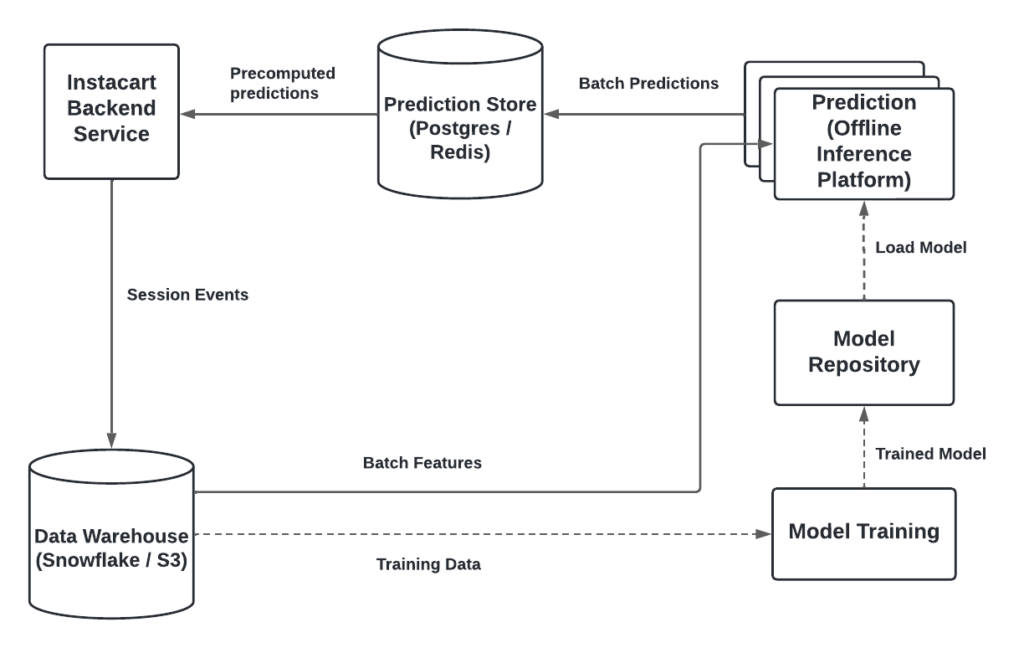
It is a natural choice for relatively small companies to start with batch-oriented ML systems since the progress can be bootstrapped by existing batch-oriented infrastructures. While some of our logistics systems were using real-time predictions using mostly transactional data and some event-driven feature computation, it was not easy to generate features and was not widely adopted across the company. Most other ML systems at Instacart started with batched-oriented systems with two main characteristics: 1) ML models only had access to batch features; 2) these models generated predictions offline in batches and consumed those predictions either offline for analytics, or online using a lookup table. Machine learning engineers could simply write the model outputs to database tables and applications could read them in production without the need for any complicated infrastructure. However, we experienced several limitations in these batch-oriented ML systems:
- Stale Predictions: Precomputed prediction offers an inferior experience in many applications since they only generate stale responses to requests that happened in the past. For example, batch prediction only allowed us to classify historical queries but performed poorly on new queries.
- Inefficient Resource Usage: It is a waste of resources to generate predictions daily for all customers since many customers are not active every day.
- Limited Coverage: This system provides limited coverage. For instance, it’s not possible to cache predictions for all user-item pairs due to large cardinality and we have to truncate the pairs in the long-tail.
- Response Lag: Models are less responsive to recent changes since real-time features, such as customers’ intents in the current shopping session and real-time product availability, are not accessible to the model.
- Suboptimal: Data freshness impacts the quality of model output. Without the up-to-date signals (such as supply and demand), the fulfillment process can be suboptimal since models do not have access to real-time changes and the lag in decision-making can lead to inefficient resource allocation.
As we introduce product innovations in the Instacart app to improve personalization, inspiration, capturing and serving dynamic features in real time becomes essential. This requires transitioning most of the ML services at Instacart from batch-oriented to real-time systems. Among other things, we have gone through the following major transitions to enable real-time ML:
- Real-Time Serving: From serving precomputed predictions to real-time serving in order to reduce staleness, limited coverage, and resource underutilization.
- Real-Time Features: From batch features to real-time features to ensure data freshness, and enable models to respond to up-to-date changes.
Transition 1: From serving precomputed predictions to real-time serving
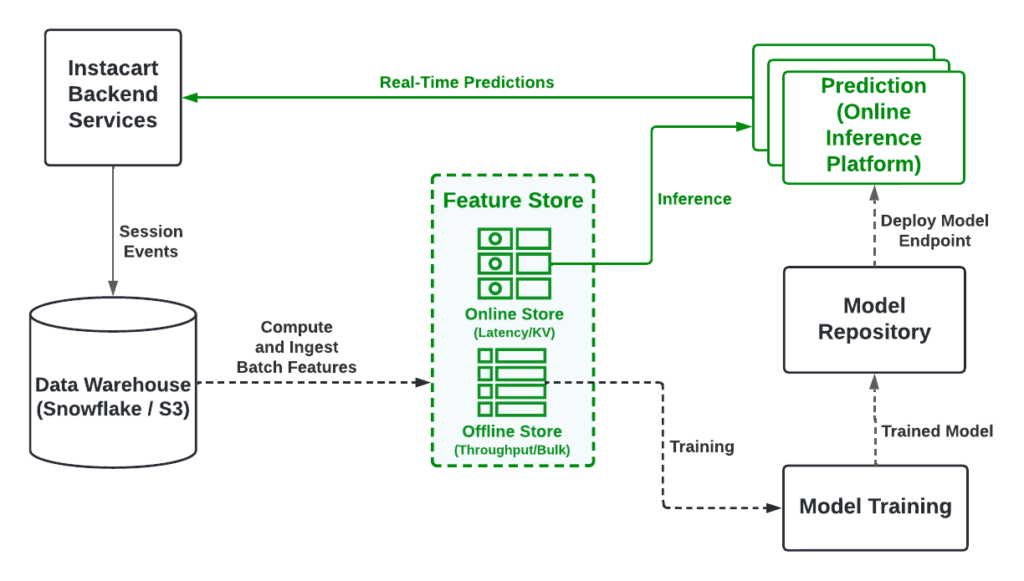
Transitioning to a real-time serving system has been made possible by two products: Feature Store and Online Inference Platform. Feature Store is a key-value store for fast feature retrieval and Online Inference Platform is a system that hosts each model as an RPC (Remote Procedure Call) endpoint. Real-Time Serving improved machine learning applications by integrating new features such as personalization, optimized computation resources by eliminating execution of unused predictions, and increased conversions by optimizing long-tail queries. Most importantly, it also provided better customer experience because it incorporated personalized results and improved results for new users/queries.
Even though the transition was a significant win for machine learning applications, introducing real-time serving introduced many technical challenges.
Challenges of Moving to Real-Time Serving
- Latency: Latency plays an important role in the user experience; no one likes to wait to see search results loading while shopping. A real-time serving system introduces dependencies on feature retrieval, feature engineering, and model prediction and makes it essential that those processes are fast and can be accessed with a tight latency budget.
- Availability: The real-time inference system introduces a failure point that can cause downtime in the backend service. Ensuring high availability of the model services necessitates better monitoring, error handling, and deployment practices.
- Steep Learning Curve: The system involves understanding many new components and processes. It was mainly challenging for machine learning engineers because it changed the development process and introduced many new tools.
Key Decisions
- Unified Interface: Developing a unified interface, Griffin, enabled us to integrate best practices such as unit tests, integration tests, and canary deployments. It also reduced the learning curve for machine learning engineers by providing standard workflow templates, and tools for fast troubleshooting. Additionally, creating a single entrypoint to our system allowed us to standardize monitoring, observability, and other processes required for reliability.
- Generalized Service Format: We chose an RPC framework that was widely used at Instacart for inter-service communications. Reusing existing tools allowed us to quickly develop a production-grade platform and support communication between multiple languages such as Ruby, Scala, Python, and Go. Furthermore, it allowed machine learning engineers to share knowledge between groups and grow faster with collaboration.
Transition 2: From batch features to real-time features
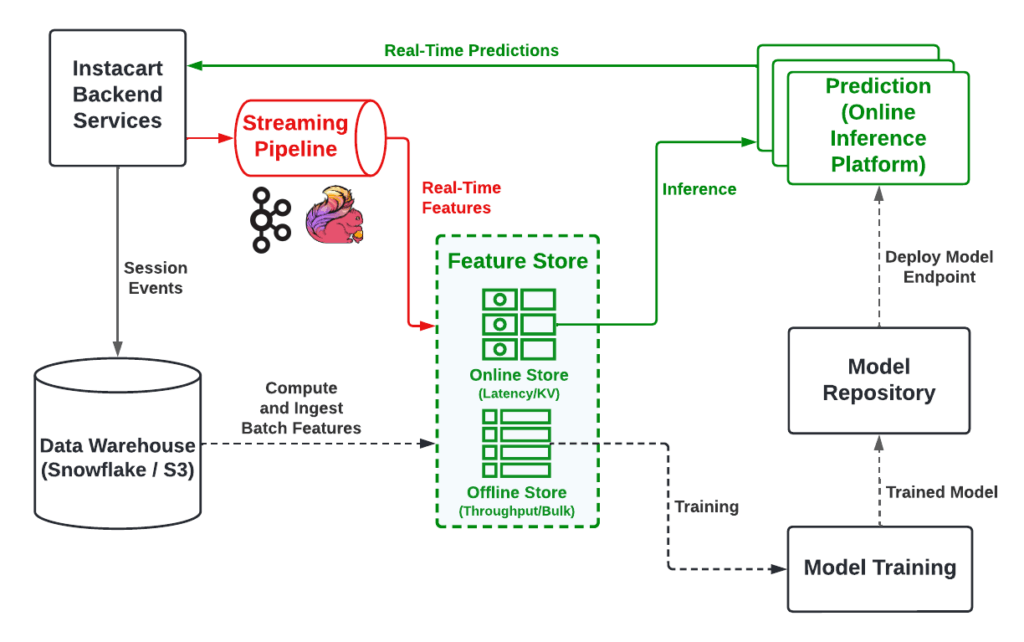
The transition to real-time serving has improved the user experience by eliminating the staleness and limited coverage of the precomputed predictions. However, all predictions are still based on batch features. The best experience in a shopping journey requires both batch features and real-time features. To enable real-time features, we developed a real-time processing pipeline with streaming technologies as shown in Figure 4. The pipeline listens to raw events stored in Kafka published by services, transforms them into desired features using Flink, and sinks them into Feature Store for on-demand access. Although streaming is a relatively mature technology, there are still quite a few challenges we faced in the transition.
Challenges
- Siloed streaming technologies in different organizations: The need for stream processing at different teams vary from simple notifications to analytics. Therefore, each organization had adopted the tools that fit its respective needs and we ended up with three different streaming tools. This works fine locally within each organization, but it is challenging for machine learning since it requires events built across different organizations.
- Event consistency and quality: Events have been mostly consumed/managed by local teams for their specific needs. This brings two challenges when consolidating events to generate real-time features: 1) it is not clear what events are available; and 2) event quality is not guaranteed.
- Complex pipeline with new development process: As shown in Figure 4, the real-time features pipeline introduces a new tech stack. It starts from raw events published by services, goes through stream processing and Feature Store, and responds to user requests in real-time. The challenges with this are twofold. On the one hand, real-time features (streaming in general) are not common knowledge for machine learning engineers and data scientists. On the other hand, it is more involved to set up a development environment for streaming processing. The fact that data streaming technologies work best in JVM (Java and Scala) with suboptimal support in Python also makes the learning curve steeper.
Key Decisions
- Centralized event storage: Given the challenging situation that there exist multiple streaming backends in different organizations, we chose Kafka as a centralized storage to put all raw events together so that we can derive ML features from them in consistent format. This introduces some extra latency to the pipeline (usually within a few 100ms) and uses some more resources, but the benefits outweigh these shortcomings. First, centralized storage scales quickly and avoids building multiple interfaces between real-time ML systems and different streaming tools. Second, this does not impact the existing event usage pattern, and centralized event storage makes it easy to integrate schema validation and data quality checks to improve the events quality.
- Separate event storage and computation: We also made the choice to have separate event storage and event computation. On the one hand, this modularizes the system by following the design principle of separation of concerns and adopts the best tools for the work. On the other hand, it provides a ground truth reference for all events in a single, durable storage with consistent format and configurable retention period. This makes data audit and compliance review easier, and supports event replay within the retention period when needed.
- Form cross-functional working groups early: Since real-time features (or real-time ML initiatives in general) are a highly cross-functional effort, early on in the process, we formed a working group among different teams with experts in product/business development, streaming technologies, and ML development. This group is critical for us to discuss and reach decisions that address our existing challenges in enabling real-time ML. It also helps us to debate and evaluate early use cases for real-time ML. For instance, thanks to the collective views of the working group, we prioritize the real-time item availability as the first use case since it is not only an essential model by itself, but also provides fundamental item availability scores that improve item found rate and customer experience, increases ETA prediction accuracy, and improves many services that require up-to-date item availability information. The success of this fundamental use case has enabled rapid adoption of real-time ML thereafter.
Retrospection
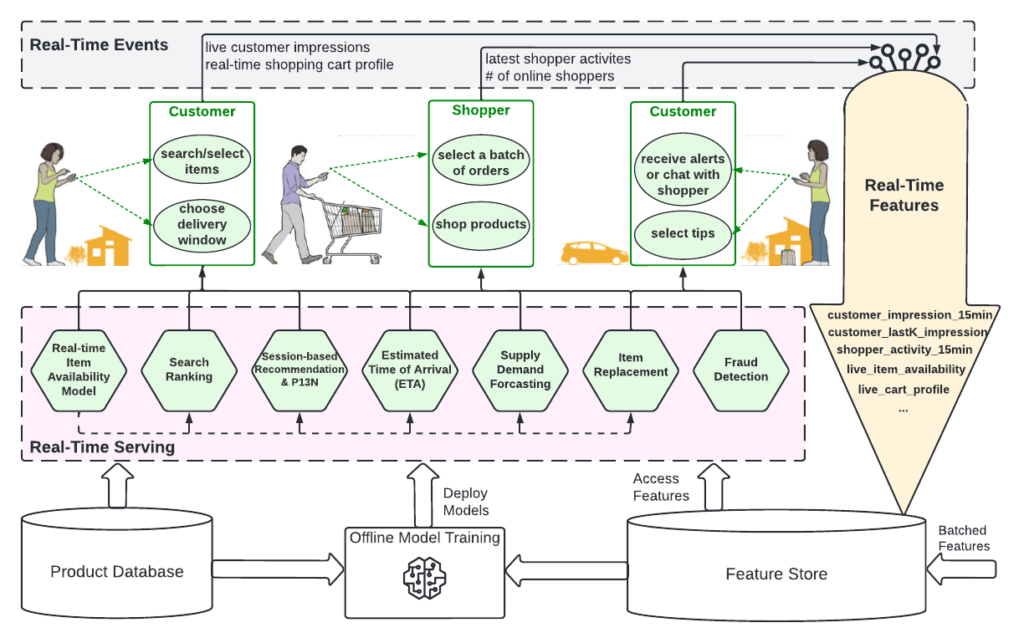
With two critical transitions and other improvements, we have created an ML platform with real-time serving and real-time features as illustrated in Figure 5. The platform transforms the shopping journey to be more dynamic and efficient, with better personalization and optimized fulfillment. Here are some highlights of the applications launched on the platform:
- Real-time item availability updates item availability scores in seconds from a couple of hours. This directly improves item found rate, reduces bad orders, and ultimately increases customer satisfaction.
- Session-based recommendation and personalization models make predictions within the shopping session in real-time. For instance, by removing items that wouldn’t be of interest to the customer based on their choices in the recent session, we have already made the Instacart storefront more fresh and dynamic with real-time user impression data.
- Fraud detection algorithms catch suspicious behaviors in real time and make it possible to prevent fraudulent activities before a loss occurs. This alone directly reduces millions of fraud-related costs annually.
Overall, the real-time ML platform flows terabytes of event data per day, generates features with latency in the order of seconds contrast to hours before, and serves hundreds of models in real time. The platform resolves the limitations of batch-oriented systems to help related ML applications go real time, and also unleashes ML applications to make more business impact. Over the last year, the platform has enabled considerable GTV (gross transaction value) growth in a series of A/B experiments.
Lessons Learned
- Infrastructure plays a critical role in real-time ML
Transitioning into a real-time system required a major investment in infrastructure tools and processes in order to achieve better observability, efficient computation, high availability, and reliable deployment. We used many tools and processes for real-time serving and real-time features which allowed us to productionize the platform quickly and show an impact at Instacart. Using a unified interface that allows a diverse set of tools was essential in our success. - Make incremental progress
Going from a batch-oriented ML system to real-time ML platform is a big step. To make it more manageable, we carried out the transition in two distinct phases as detailed above. We also identified at least one impactful use case to start with for each transition. As a result, in each transition phase, we have a clear goal and the incremental impact can be easily measured. This not only enabled a more gradual platform update but also reduced the learning curve for machine learning engineers who adopted the platform. - Generalized and specialized solutions
We adopted a generalized solution that helped us cover the majority of the cases with excellent support. To accelerate the development, we then started building more specialized products such as an Embedding Platform to focus on more targeted circumstances and reduce the support requests. This balance between generalization and specialization improves the productivity for those specialized use cases, and achieves high reliability in the overall system. - Grow infrastructures with products
Machine learning engineers who adopted our platform during early development played a significant role in improving the quality by providing feedback and in growing the adoption by marketing the platform to other product teams at Instacart.
Instacart
Instacart is the leading grocery technology company in North America, partnering with more than 1,400 national, regional, and local retail banners to deliver from more than 80,000 stores across more than 14,000 cities in North America. To read more Instacart posts, you can browse the company blog or search by keyword using the search bar at the top of the page. Building for Balance
Building for Balance  Griffin: How Instacart’s ML Platform Tripled ML Applications in a year
Griffin: How Instacart’s ML Platform Tripled ML Applications in a year  How Instacart Uses Machine Learning-Driven Autocomplete to Help People Fill Their Carts
How Instacart Uses Machine Learning-Driven Autocomplete to Help People Fill Their Carts  Building Instacart Pickup
Building Instacart Pickup 

Most Recent in How It's Made

How It's Made
One Model to Serve Them All: How Instacart deployed a single Deep Learning pCTR model for multiple surfaces with improved operations and performance along the way
Authors: Cheng Jia, Peng Qi, Joseph Haraldson, Adway Dhillon, Qiao Jiang, Sharath Rao Introduction Instacart Ads and Ranking Models At Instacart Ads, our focus lies in delivering the utmost relevance in advertisements to our customers, facilitating novel product discovery and enhancing…...
Dec 19, 2023
How It's Made
Monte Carlo, Puppetry and Laughter: The Unexpected Joys of Prompt Engineering
Author: Ben Bader The universe of the current Large Language Models (LLMs) engineering is electrifying, to say the least. The industry has been on fire with change since the launch of ChatGPT in November of…...
Dec 19, 2023
How It's Made
Unveiling the Core of Instacart’s Griffin 2.0: A Deep Dive into the Machine Learning Training Platform
Authors: Han Li, Sahil Khanna, Jocelyn De La Rosa, Moping Dou, Sharad Gupta, Chenyang Yu and Rajpal Paryani Background About a year ago, we introduced the first version of Griffin, Instacart’s first ML Platform, detailing its development and support for end-to-end ML in…...
Nov 22, 2023