How It's Made
Building a Flink Self-Serve Platform on Kubernetes at Scale

Author: Sylvia Lin
At Instacart, we have a number of data pipelines with low-latency needs that handle over two trillion events a year. Those events help our engineering and product teams to make better decisions and gain deeper business insight. In order to leverage those real-time events for our business expansion, we adopted Apache Flink in late 2021 as our real-time distributed processing engine. Flink offers nice features like low latency, high throughput, strong guarantees, state management, and easy replay.
To date, we’ve used Flink to meet a range of needs:
- Real-time decision making, like fraud/spam detection
- Real-time data augmentation, like Catalog data pipelines
- Machine Learning real-time feature generation
- OLAP events ingestion for our experimentation platform
We accomplished all of this running Flink on AWS’ EMR, but as we grew we realized we needed a more robust self-serve Flink platform for our teams. We’ll talk about why this is, and describe the new platform that we built on Kubernetes.
How the Flink platform helps process our data and events
The Flink platform as our core streaming computation engine has been a tremendous help in processing our data and events. It enables us to process and analyze large amounts of data in real time with high scalability and reliability.
Flink’s streaming architecture allows us to process data as soon as it arrives in the system, without having to wait for large batches of data to be collected. For example, we use it as our real-time event router. This allows users to route events from single event ingestion Kafka topic to their own sub Kafka topic within a few milliseconds.
Furthermore, Flink’s distributed architecture allows us to process large volumes of data in parallel. As our OLAP data loading service we can achieve throughputs well beyond what a single machine could handle.
Finally, Flink’s extensive library of connectors and APIs allows us to integrate with a wide range of data sources/sinks and applications, allowing us to gain insights from data in ways that weren’t possible before.
The challenges of scaling Flink platform on EMR clusters
When we began using Flink as our streaming computation engine, we deployed all our Flink jobs on AWS EMR clusters. Running Flink on EMR clusters was a great starting point, as EMR clusters come with the big data frameworks such as Flink and Hadoop by default. In the past 10 months, we onboarded more than 50 product teams running their Flink pipelines. Internally within the Data Infra team, we added 500 Flink data ingestion pipelines. To meet the high demand, we needed to delegate job ownership to product teams and make our platform self-serve. Running Flink on EMR did not scale to meet such a high demand. In addition, the lack of native tooling makes Flink self-serve difficult for running on EMR.
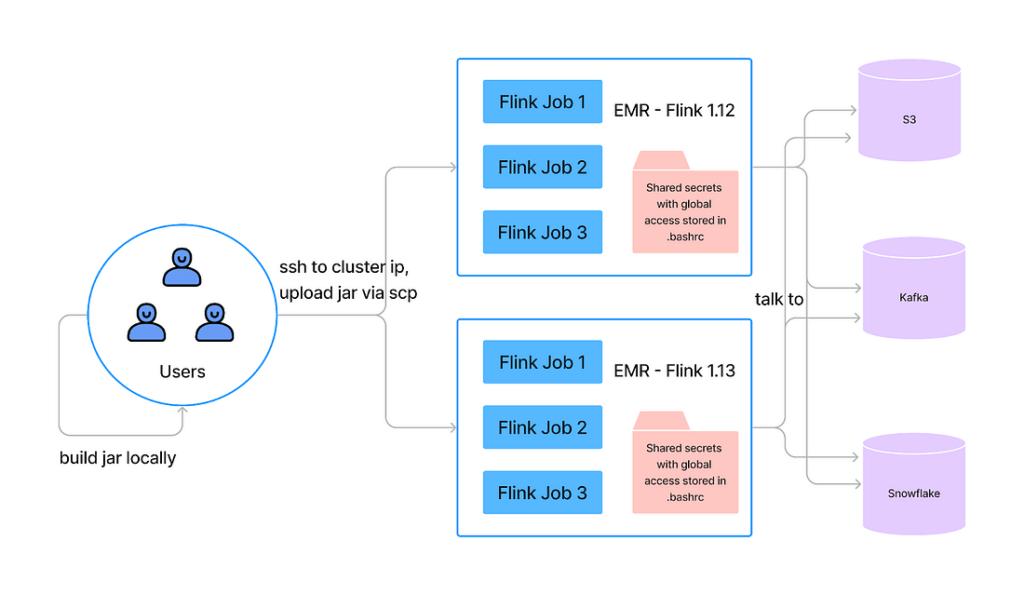
The Flink on EMR flow is demonstrated in the diagram below. It has a couple of major issues:
- Lack of secrets or config management for services, no service level resources isolation.
- The AWS permission model can only be applied to cluster level on EMR, so to accelerate service onboarding, all services are running with global permissions.
- Users have to interact with the cluster nodes via SSH for job management. No security and auditing tools installed on the clusters.
- No good auto scaling mechanism support on EMR or job failure recovery mechanism. Flink service operation burden is high as a result.
- No multi-flink version support on a single EMR cluster, and our Flink services run between Flink 1.12 to Flink 1.15. As a result we have to manage ~75 EMR clusters.
- No CI/CD support. Running Flink on EMR is not containerized, so it cannot be integrated with Instacart standard CI/CD pipeline.
With the increasing number of Flink jobs we host, the major issues listed above represent a reliability threat for our real-time data pipelines, and limit our team operation/support capacity.
Our next generation Flink platform on Kubernetes
Kubernetes (aka K8S) is an open source container orchestration platform that allows us to easily deploy, scale, and manage applications and services. By adopting it, we can now easily manage applications while also taking advantage of its built-in fault tolerance and autoscaling capabilities. In addition, it provides a ton of well-supported tools.
Built-in fault tolerance and autoscaling make it easier to quickly react to changes in load, while also ensuring that applications are always running optimally. Leveraging Kubernetes tools helps deploying applications in a standard way with minimum engineering effort.
Official support for Flink on Kubernetes was introduced in 2019, and this approach has become more and more popular recently. The Flink community also officially introduced their Flink K8S operator project in early 2022, which significantly reduces human operational load and maintenance costs.
Below is our Flink platform workflow on EKS (Amazon Elastic Kubernetes Service):
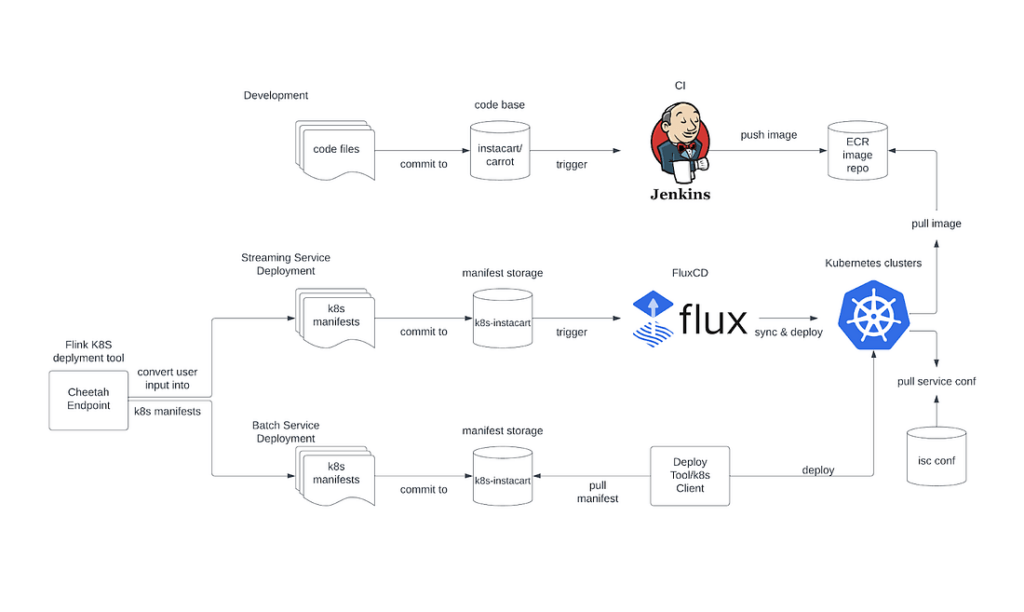
- The new service provisioning/onboarding is done by one endpoint (Cheetah Endpoint) request, and is powered by Instacart Flink K8S Custom Controller. The Instacart Flink CRD(Customer Resource Definition) is the abstraction of Instacart Flink deployment, which consists of all required permissions/Kubernetes resources and a default Flink deployment config. And the Custom Controller accepts this CRD from our Cheetah Endpoint, then deploys this to the Kubernetes cluster and periodically resyncs their states.
- The development flow is integrated with Instacart’s standard CI flow, which automatically builds application images and pushes them to our ECR (Amazon Elastic Container Registry) repository.
- The deployment flow takes the idea from GitOps, and it is done by a FluxCD integration, which keeps monitoring changes on our K8S manifest repo.
- The service configs and secrets are managed by Instacart’s config manager (isc conf). It provides a nice UI with search/create/replace by exact name matching or regex.
- Service management — such as failure recovery, checkpoint restoring, and running status check — is done by the Flink K8S operator.
- Each service runs on its own namespace and service account. The service’s permission is tied with the namespace and service account pair.
- Flink’s UI is accessible through NGINX ingress, and logs are persisted in Datadog.
- Karpenter is used for cluster node management. Before introducing Karpenter, we had to allocate multiple node groups for our multi-tenant cluster to meet certain complex Flink deployments resource isolation requirements since running state changes for these large/complex Flink deployments significantly disturbs node allocation for the node group they’re running. Karpenter solves this problem neatly, by introducing the concept of just-in-time nodes, allocating right-sized nodes from the start, providing better bin packing for the Flink tasks, and since it directly manipulates the nodes through EC2 Fleet API calls, it has superior, finer control over the machines, compared to the current autoscaling-based managed node groups + cluster-autoscaler.
Impact and Learnings
Originally, we had an 8-page guide for new Flink pipeline onboarding, and there were several manual steps that made the process error-prone. This significantly reduced our developer’s productivity, and increased our data platform engineers support time. With Kubernetes technology and a self-developed Instacart Flink K8S controller, we encoded our Flink deployment model (AWS permissions, Kafka permission, default Flink setting) into a simple model. This reduces the new Flink pipeline onboarding time from one week to a few minutes. The results were very positive:
- Decreased operation costs. With tools and automation such as CI/CD, NGINX controller, Lacework, Teleport, we are able to significantly reduce our operation, support and troubleshooting effort with very minimum development effort, while also providing a good user development experience. It overall saved us about 50 weeks of development effort, 20% engineering effort on operation and support, and 15% on development productivity.
- Infra cost saving. By leveraging the smart auto scaling mechanism, along with capabilities like Node Affinity, we are able to schedule loads with different resource patterns on a single mixed node type cluster. This saves 50%+ infra cost on production instances, 70% on dev instances, and 40% on EBS volumes.
- Auto failure recovery, and zero incident even during traffic peak season. By deploying Flink K8S operator, we are able to achieve auto failure recovery without manual intervention. It helps to reduce about 30 critical alerts to 0 every year, which is particularly impactful given many of these critical alerts happened at night.
We’re really excited about all the achievements enabled by Kubernetes and Kubernetes tools. Below are our learnings and takeaways.
- The entire Flink service onboarding and operations should be streamlined without K8S details. Most of our platform users don’t have knowledge of Kubernetes, so we should abstract K8S details as much as possible.
- It’s important to build our real-time system with a platform mindset and unified technologies and tools. Short term solutions with heterogeneous technologies make the platform inefficient and hard to scale and operate– and Kubernetes is currently the most prominent solution to provide this unification. It provides a way to manage everything we need in a single place, that we used to require more than 3 systems to manage. Kubernetes support is iterating super fast on Flink’s roadmap, and it’s a big step to make Flink more cloud native. We have witnessed significant evolution for Flink K8S operator during 2022, with a ton of nice features enabled.
Acknowledgements
Special thanks to Luiz Soares, who is the lead engineer from our Cloud Foundations team, who set up all fundamental infrastructure for Flink Platform running on EKS, and provided invaluable advice throughout the whole project. And Ben Bader, who helped build the Flink developer experience tools on top of Kubernetes, enabling the smooth self-serve experience.
Applause to our infra engineers who directly contributed to this project: Christopher Cope, Francois Campbell, Greg Lyons, Han Li, Jocelyn De La Rosa, Justin Poole, Peerakit Somsuk, Shen Zhu, Xiaobing Xia.
And thanks to the many other engineers for their contributions and in making this a successful project. Additional thanks as well to Instacart Cloud team and Build and Deploy team for their support!
Instacart
Instacart is the leading grocery technology company in North America, partnering with more than 1,400 national, regional, and local retail banners to deliver from more than 80,000 stores across more than 14,000 cities in North America. To read more Instacart posts, you can browse the company blog or search by keyword using the search bar at the top of the page. Building Instacart Meals
Building Instacart Meals  7 steps to get started with large-scale labeling
7 steps to get started with large-scale labeling 

Most Recent in How It's Made

How It's Made
One Model to Serve Them All: How Instacart deployed a single Deep Learning pCTR model for multiple surfaces with improved operations and performance along the way
Authors: Cheng Jia, Peng Qi, Joseph Haraldson, Adway Dhillon, Qiao Jiang, Sharath Rao Introduction Instacart Ads and Ranking Models At Instacart Ads, our focus lies in delivering the utmost relevance in advertisements to our customers, facilitating novel product discovery and enhancing…...
Dec 19, 2023
How It's Made
Monte Carlo, Puppetry and Laughter: The Unexpected Joys of Prompt Engineering
Author: Ben Bader The universe of the current Large Language Models (LLMs) engineering is electrifying, to say the least. The industry has been on fire with change since the launch of ChatGPT in November of…...
Dec 19, 2023
How It's Made
Unveiling the Core of Instacart’s Griffin 2.0: A Deep Dive into the Machine Learning Training Platform
Authors: Han Li, Sahil Khanna, Jocelyn De La Rosa, Moping Dou, Sharad Gupta, Chenyang Yu and Rajpal Paryani Background About a year ago, we introduced the first version of Griffin, Instacart’s first ML Platform, detailing its development and support for end-to-end ML in…...
Nov 22, 2023