How It's Made
Adopting PgCat: A Nextgen Postgres Proxy

Authors: Mostafa Abdelraouf, Zain Kabani, Andrew Tanner
In this post, we’ll be talking about PgCat, an open-source Postgresql Proxy that we have been using in production and contributing to. It provides connection pooling, load-balancing, and replica failover for our Postgresql clusters.
At Instacart, we use Postgresql for the vast majority of our database needs. We can squeeze a lot of performance out of a single instance of Postgres with effective caching, indexing, query optimization and vertically scaling instances. All these strategies are great but they can only go so far. We can scale beyond one instance by adding more read replicas or horizontally sharding the database. Both techniques, however, come at the cost of added complexity.
For example, when using read replicas, the application needs to know how many replicas there are, it needs to be able to effectively load-balance between them, route traffic away from a degraded replica, and understand the concept of replication lag.
Historically, we have solved these problems on the application side using libraries such as Makara, Makara is a Ruby gem that operates as an ActiveRecord connection adapter that handles load balancing and failover. However, Makara comes with its own set of shortcomings, and more importantly, it is a Ruby-only solution. Ideally, we want to be able to solve this problem for all clients regardless of language.
The proxy layer that sits between our clients and the database is the ideal position to implement these functions because communication to and from the proxy layer is done using the Postgres protocol which is language-agnostic. At Instacart, this proxy layer has been occupied by the venerable PgBouncer. Pgbouncer does connection pooling very well but does not support replica failover and has limited support for load balancing.
Because of these limitations with PgBouncer, we decided to explore other options and concluded that PgCat is well-suited to meet our needs into the future. We’ll explain why we decided to use PgCat, how it compares to PgBouncer, and some of the features we developed for it.
Why PgCat?
As we said, we want a Postgresql proxy that goes beyond connection pooling. So in addition to being at feature parity with PgBouncer, we would like the proxy to handle load-balancing and replica failover. We also want to be able to safely extend the proxy with more features in the future.
We evaluated a few options. Below is a summary of the features provided by each of these options (Pgpool was eliminated from contention for its lack of support for transaction mode):

During the course of our investigation, we learned from our friends at PostgresML about the new Postgres proxy they are working on called PgCat. It supported the majority of the features we want in addition to being written in Rust. Being written in Rust is an upside because the memory safety guarantees that Rust provides allow us to build concurrent features without sacrificing safety or speed.
Evaluating PgCat
When we were introduced to PgCat it was in beta, and it was missing some features we care about such as multiple pools per instance and graceful shutdown. We contributed these features to PgCat and started testing the proxy in our sandbox environments and later in our production environments. Maintaining parity with Pgbouncer in terms of latency and correctness was especially important for us.
Latency
We tested the latency by configuring a service to use PgCat as one replica, PgBouncer as another replica, and relied on a client-side library to balance the load between the two. This allowed us to perform an apples-to-apples, end-to-end latency comparison.
Under our production workloads, we saw that PgCat’s latency profile closely tracked PgBouncer’s. Below we show the end-to-end query latency percentiles on both proxies. The sample size for the data below is ~1.5M production queries performed over the span of 12 hours.
| PgBouncer | PgCat | Difference | |
| p50 | 4.68ms | 4.69ms | +10μs |
| p75 | 6.72ms | 6.78ms | 60μs |
| p90 | 10.8ms | 10.9ms | 100μs |
| p95 | 14.8ms | 15.0ms | 200μs |
| p99 | 26.8ms | 27.8ms | 1ms |
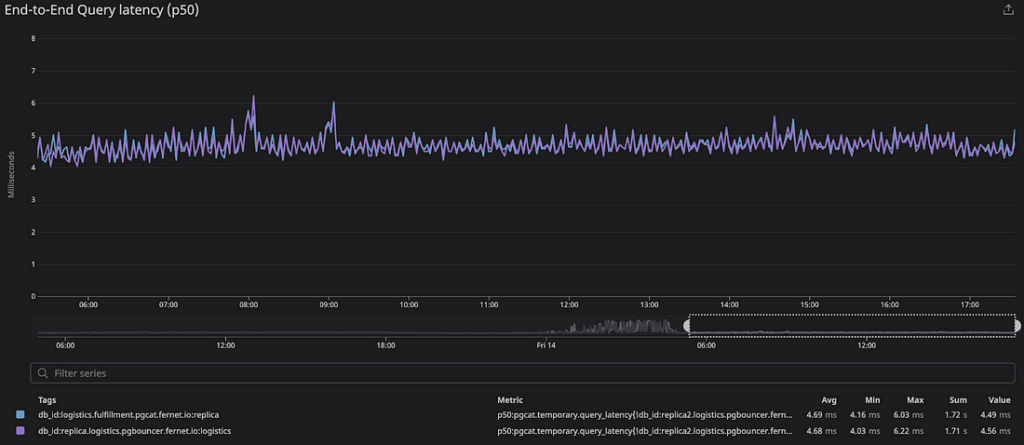
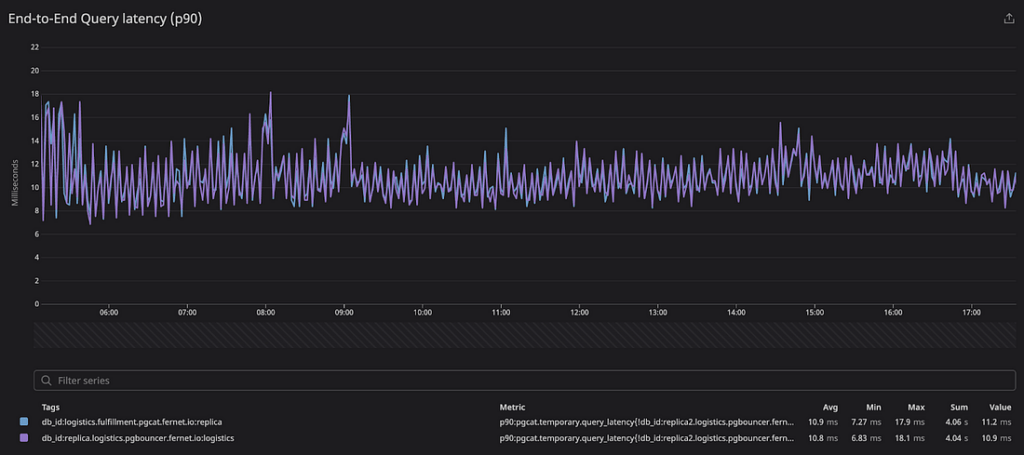
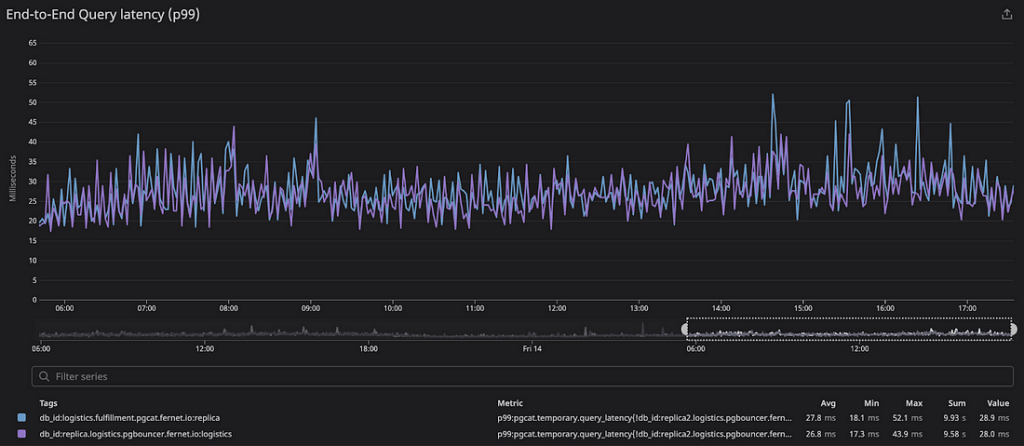
Overall, we didn’t see any noticeable impact on service latency when switching to PgCat.
Correctness
On the correctness front, we wanted to ensure that the proxy handles the protocol correctly when communicating with the database, and the clients and that PgCat as a connection pooler behaves like PgBouncer.
We tested this by subjecting the proxy to synthetic loads, testing it against different query patterns in production environments, and against different clients (both well-behaved and poorly-behaved). We also tested PgCat support for PgBouncer control commands such as RELOAD, SHOW POOLS, etc. We use these commands to monitor and control our PgBouncer fleet and wanted to be sure PgCat would plug into these existing PgBouncer tools we have. We identified a few issues and contributed fixes to them (graceful shutdowns, multi-user pooling) and we’re at a point now where PgCat is handling our production workloads without any issues.
How does PgCat differ from PgBouncer?
PgCat was built to be a drop-in replacement for PgBouncer. It supports session/transaction modes, in addition to PgBouncer control and statistics commands, multiple users, and multiple pools. But where does PgCat differ from PgBouncer?
Architecture
PgCat is a multi-threaded proxy written in Rust using the Tokio asynchronous runtime. Pgbouncer is a single-threaded proxy written in C based on libevent.
Deployment Layout
PgCat can be placed in front of a single database instance and it would behave like PgBouncer (see Layout A and B below) but in order for the application to gain load balancing and failover features, a PgCat instance should be allowed to connect to multiple instances in a replication cluster. This could be the primary and all replicas, all replicas without the primary, or a subset of the replicas. PgCat won’t be able to load-balance or failover if each PgCat instance can see only one database instance.
This can be achieved in a variety of ways:
- Multiple containerized PgCat instances deployed behind a load balancer and each instance can connect to multiple databases in the cluster.
- Single PgCat instance running on a multi-core host separate from the database.
- Multiple PgCat instances co-located on the database machines but allowed to talk to other database instances in the cluster.
Each of these has its upsides and downsides, but one key point to note is that PgCat is multi-threaded so it can benefit from more CPU cores on the machine it runs on.
At Instacart, we use the containerized layout with replicas (Layout C), and we generally split our instances into two pools, one for the primary only and another for all the replicas.
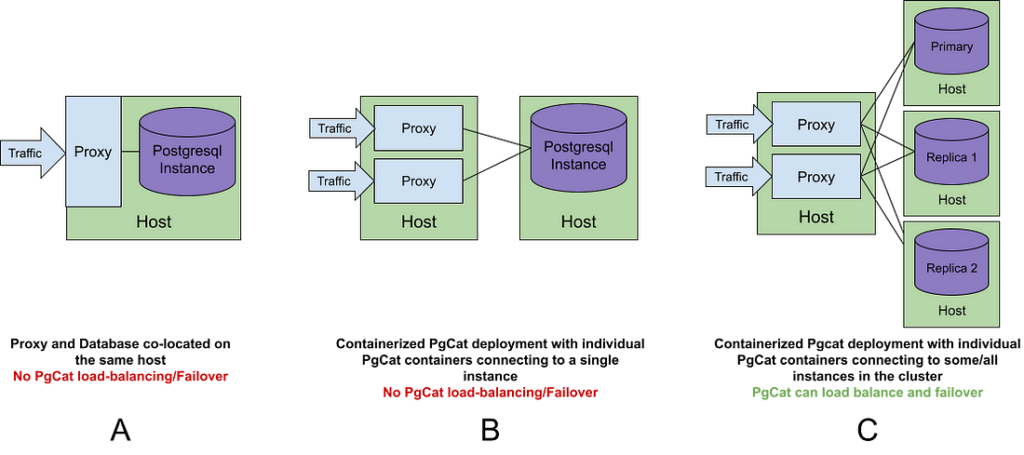
Features
Load balancing
PgCat allows us to place multiple database instances in a pool and then load-balance across these instances. This is a big win in simplifying application code which now only has to worry about connecting to a single database endpoint.
Currently, PgCat supports two load balancing algorithms, random and least connections. Random load balancing simply selects a random instance from the pool, and this strategy performs better than round-robin as we will explain later. Least connections sends queries to the instance with the least number of checked-out connections, and this strategy works best with heterogeneous workloads or pools with differently-sized database instances, and it also allows for quicker response to transient replica slowdowns.
Replica failover
In a multi-replica setup, we want to be able to route traffic away from a failed replica until it recovers. If we quickly detect the downed replica, we will see less application impact. When PgCat detects a replica outage, it bans that replica from being used for some amount of time (defaults to 60 seconds).
PgCat bans a replica in one of the following situations:
- A post-checkout health check query times out or fails.
- A client encounters connection loss while connected to a replica.
- A client timed out while waiting to check out a connection to that replica from the pool.
- A query exceeds the configured PgCat statement timeout (PgCat statement timeouts are disabled by default).
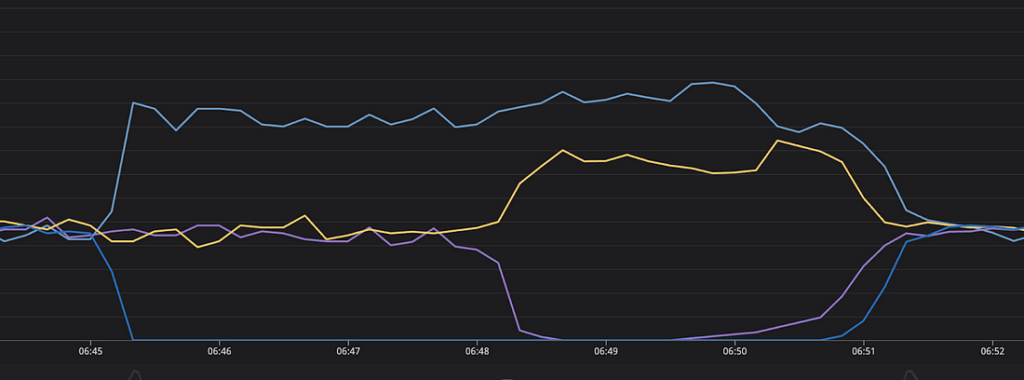
As mentioned earlier, Replica banning can lead to load imbalance when used in conjunction with round-robin. This prompted us to use random load balancing instead. To understand the issue, let’s consider a system with 4 replicas: clients will go through these replicas in order (albeit with different starting points), which means replica 3 will always be attempted after replica 2, and replica 4 will always be attempted after replica 3, etc.
This will become problematic when we ban a replica because this will lead all clients using the banned replica to try the next one which will resolve to the same instance for ALL clients. For example, if we ban replicas 2 and 3 then all traffic from these replicas will end up on replica 4 because it is the next one in line for all of these clients. This effect should be transient, but in our experience, the effect seems to be persistent. When we updated PgCat to use random load balancing, the imbalance went away.
Handling misbehaving clients
A misbehaving client is a client that disconnects from the proxy at a bad time. Examples include:
- A client that opens a transaction and then disconnects while the transaction is open.
- A client disconnects while a query is in-flight.
PgBouncer handles these cases by closing the corresponding server connection. This can become a problem if it happens too frequently, as it can result in significant server connection thrashing. In our experience, such events can be detrimental to database performance. PgCat is able to salvage the server connection in these situations by sending a ROLLBACK query to the server connection and putting it back in the pool.
Support for sharded databases
PgCat supports sharding as a first-class concept. It allows the application to select the shard it wants to talk to using the sharding key or the shard number. This is a feature that we haven’t used in production workloads yet but we are planning to.
Current state
PgCat has been in use for some of our unsharded production workloads for the past 5 months. The peak throughput is about 105k QPS across several ECS tasks. The peak throughput per task was around 5.2k QPS. Clients varied in their language and usage patterns including Ruby, Python, and Go: all were able to migrate to and use PgCat without issues or changes being required.
We’ve been able to successfully migrate one of our largest databases to PgCat and this has yielded significant benefits by adding load balancing to services that were lacking them, handling several database outages, and allowing us more easily perform maintenance on database instances.
We are currently working on moving more of our production workloads to PgCat and considering PgCat for our sharded database clusters.
PgCat is targeting a 1.0 release in the coming weeks! The project is also actively looking for more contributors and adopters, the issue list can be found here. We think it’s a great project, and encourage anyone who’s interested to get involved.
Instacart
Author
Instacart is the leading grocery technology company in North America, partnering with more than 1,400 national, regional, and local retail banners to deliver from more than 80,000 stores across more than 14,000 cities in North America. To read more Instacart posts, you can browse the company blog or search by keyword using the search bar at the top of the page. Building Instacart Meals
Building Instacart Meals  7 steps to get started with large-scale labeling
7 steps to get started with large-scale labeling 

Most Recent in How It's Made

How It's Made
One Model to Serve Them All: How Instacart deployed a single Deep Learning pCTR model for multiple surfaces with improved operations and performance along the way
Authors: Cheng Jia, Peng Qi, Joseph Haraldson, Adway Dhillon, Qiao Jiang, Sharath Rao Introduction Instacart Ads and Ranking Models At Instacart Ads, our focus lies in delivering the utmost relevance in advertisements to our customers, facilitating novel product discovery and enhancing…...
Dec 19, 2023
How It's Made
Monte Carlo, Puppetry and Laughter: The Unexpected Joys of Prompt Engineering
Author: Ben Bader The universe of the current Large Language Models (LLMs) engineering is electrifying, to say the least. The industry has been on fire with change since the launch of ChatGPT in November of…...
Dec 19, 2023
How It's Made
Unveiling the Core of Instacart’s Griffin 2.0: A Deep Dive into the Machine Learning Training Platform
Authors: Han Li, Sahil Khanna, Jocelyn De La Rosa, Moping Dou, Sharad Gupta, Chenyang Yu and Rajpal Paryani Background About a year ago, we introduced the first version of Griffin, Instacart’s first ML Platform, detailing its development and support for end-to-end ML in…...
Nov 22, 2023