How It's Made
Catalog Localization: more than just a translation!

You moved to Quebec and started to learn French and use it in your daily life, even in every app you use. You even changed the language on your phone! How excited you must have been to open Instacart and discover that you can buy your baby carrots in French!

You can purchase your favorite socks with trucks in French as well!
Let me tell you about all the work we had to do to enable this experience, and why localization is always a challenge that requires deep thought and care.
First of all, localization is one of the core features required for any business that wants to tackle other languages and/or expand outside of its initial territory. Instacart started its expansion into Quebec this year and the Instacart Catalog team was the very first org that had to tackle localization so that other teams and other services can consume and use localized catalog data.
Before we dive in further, here’s some context on what the Catalog team does and what we were up against when we took on this task of localization. Almost every business today has a catalog. Would it be a catalog of users, a catalog of books, or a catalog of products? Instacart has its own catalog which stores all of the products, tracks all of the properties for these products, and powers its entire business. Moreover, Instacart’s catalog is constantly updated, and these updates are coming from a variety of sources: our partners, third-party companies, internal edits, machine learning, and more. To make it even more interesting, all of these sources push updates to our catalog whenever they want to. A web of complex systems processes them, making thousands of tough decisions in order to choose the best-in-class value for each attribute. At the end of the pipeline, our customers can see the latest and greatest updated products that they like. Catalog hides all this complexity so that customers can enjoy the highest quality data.
Instacart has the largest grocery catalog in the world, with millions of unique products, spanning over 65,000 locations across North America. To keep it up to date, we update billions of rows of data every day.
Catalog quality and accuracy play an important role for all 4 sides of the business: end customers, Instacart shoppers, retailers, and CPG partners. Every party relies on the catalog for their own reasons:
- End customers want to see accurately represented products when they browse the marketplace.
- Instacart shoppers want to make sure they can choose correct replacements when they are unable to find the desired item.
- Retailers want to see very diverse storefronts, with a huge variety of products.
- CPG partners want to have high-quality products and values behind them, so they can properly place ads where they see fit.
Overall, Catalog plays a critical and core role for our retailers and business overall. The system is built with scale in mind, from a performance and throughput perspective and from operational support as well. Almost every single team within Instacart depends on Catalog, and so making major changes to it is always a delicate task.
How Catalog is structured
Now we know how Catalog plays an important role within Instacart’s architecture, let us take a quick look at the catalog’s data structure. How does that baby carrot that you add to your cart on instacart.com look like behind the scenes? If we put this carrot into a diagram it would form a tree:
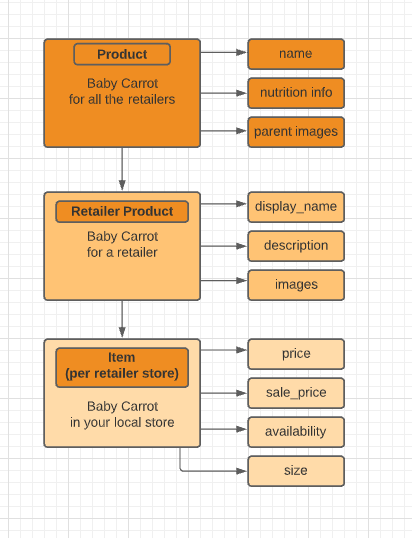
As you can see there is a parent product that has the majority of attributes; you can think of it as a parent product for all our retailers.
Then there is a retailer-level product, which has its own overwrites for some of the product-level attributes as well as its own attributes. Think of this as how a particular retailer thinks about baby carrots — it might have its own in-house image or unique description.
The final piece here is a store-level product, which contains store-level overwrites for some of the retailer-level and parent-level attributes. Think of this as a unique item in the specific physical store location — it has its own price, might or might not be available in that store, or has its own promotion for half price this week.
This is the beauty of Instacart’s Catalog Data Structure: it is very flexible and yet very powerful at the same time.
Now, where would we put localization here? What kind of attribute is it?
We put deep thought into identifying both locale-specific vs. locale-agnostic attributes. That allows us to keep our catalog highly configurable and easily adjustable to new requirements when there is a need. For example, the price is the same regardless of the language you are browsing the shop in. Let us now attach locale to our core data structure and see how it changes things.
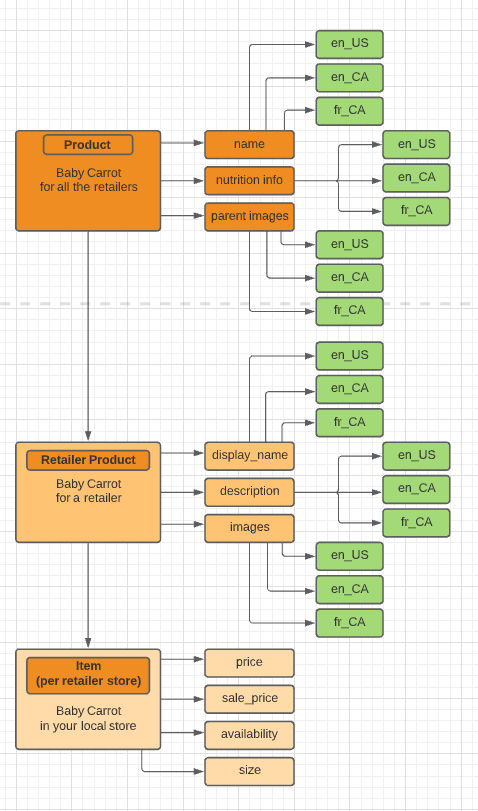
As you can see from this diagram above, the tree now expands further. Now we have localized attributes for product and retailer-product entities, and because there is nothing locale-specific about the store-level data, it remains unchanged.
New Verticals, aka Non-Grocery Expansion
Instacart started its expansion into Quebec this year and the Instacart Catalog team was the very first org that had to tackle localization
On top of that, Instacart started to onboard non-grocery retailers that add a variety of other products to end customers, such as electronics, makeup, clothes, and even some home goods, all of which have their own uniqueness. A good example would be lipstick, where you have multiple colors (different variations of the same product):
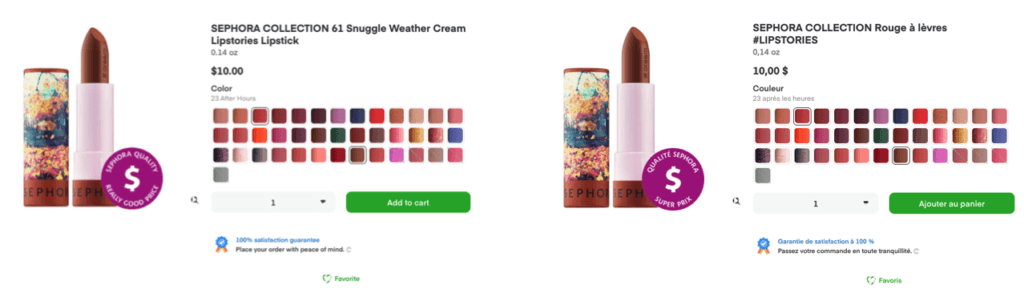
These variations need to be represented on the storefront as a single product with multiple different parameters (color, size, format, etc.).
The challenge here is that Instacart is not building its own catalog of products. We actually get catalogs from our partners and normalize them to our understanding. This means internal cross-service communications have generic contracts, and the final user experience is the same for everyone.
All these different parameters require a generic data structure that is scalable, flexible, extensible, easy to use by retailers, and also easy to navigate for a storefront team. Localization adds another layer of complexity to such non-grocery retailers as well, as everything within these variations needs to be localized.
In order to accomplish this and extend our catalog to support localization for product variations, we split up the variations into multiple pieces. One part of the feature would drive the setup for variations and control the bare bones of its configuration. This would allow us to keep the variation feature in a clean and configurable state, and additionally, the data won’t be multiplied due to localization for its own sake.
Another part would localize the actual values of the product variations. This part is accomplished via data-mapping that is applied to the retailers’ provided catalogs and Instacart’s normalized catalog.
And once more, we need to make sure that localization is flexible enough so that we can provide different localized values per store. There are rare use cases where the same variant has a different value based on the location in which it’s bought.
Raw Data
All these different parameters require a generic data structure that is scalable, flexible, extensible, easy to use by retailers, and also easy to navigate for a storefront team.
At this point, we have localized all normalized data, but there was one more challenge presented by some non-grocery retailer partners in Quebec.
First of all, acquiring, normalizing, prioritizing, and finally vending catalog data is a very complex sequence of operations that removes almost all the burden from our retailers. Catalog transforms flat files of raw data into a normalized complex data structure which is used across the company by almost all the teams all the time. In order to achieve such a unique experience and ability to acquire and ingest the biggest grocery catalog in the world, we built a set of configurable, flexible, and scalable tools around this system. This allows us to make it as easy as possible for our retailers to use.
Now here’s the catch: the way the majority of our retailers integrate their catalogs with Instacart is through sending us files that we ingest. Some of our retailer partners, however, have quite complex catalogs each with unique features. For example, some catalogs are in JSON format vs. CSV format, which the majority of retailers we work with use. While Instacart supports JSON, we must still work around the way some JSON files are structured as well as what data they provide.
An example here would be a single JSON file that has all sorts of data for all retailers’ stores across the US and Canada, which includes localization as well.
In order to tackle this, the Catalog team came up with a pretty neat approach of “flattening” nested JSON objects into a flat JSON object from this:

To this:
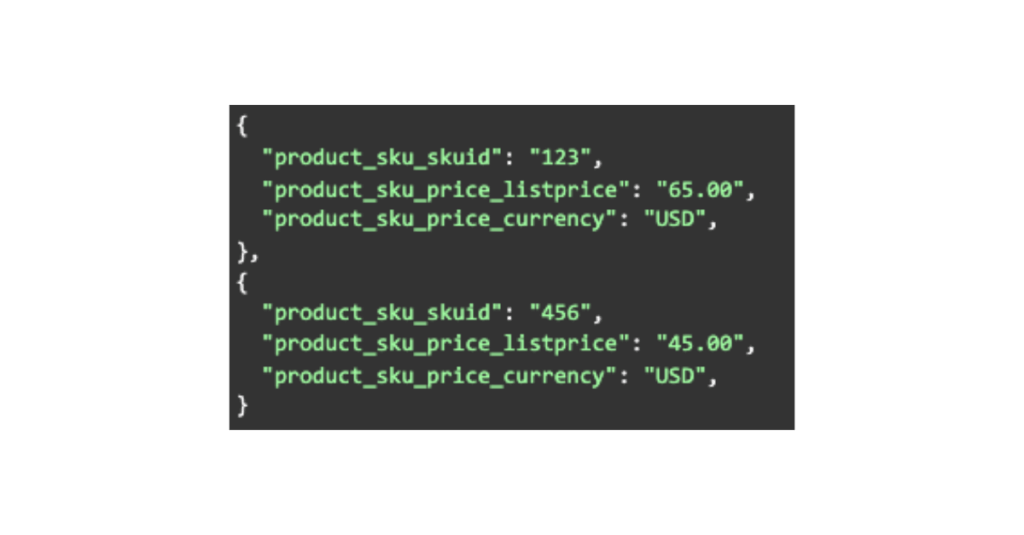
This allows us to properly standardize such raw feeds and prepare for a more in-depth and detailed normalization step. With such unique retailers, we had to broaden our onboarding features and capabilities, which better prepares us for the next retail partner, which will be unique in its own way.
Once the raw data was prepared for normalization, we had to look around for localized variant attributes within the already flattened JSON object and properly map them to our internal normalized attributes. In order to accomplish this, Catalog employed this pretty neat feature: Column Mapping. We will save a more detailed overview of what it is and how it works for a future post; it totally deserves its own!
Epilogue
With localization in place in time for our Quebec launch, with both grocery and non-grocery retailers, we are now more ready than ever to tackle the next i18n challenge.
Merci d’avoir choisi Instacart!
Instacart
Instacart is the leading grocery technology company in North America, partnering with more than 1,400 national, regional, and local retail banners to deliver from more than 80,000 stores across more than 14,000 cities in North America. To read more Instacart posts, you can browse the company blog or search by keyword using the search bar at the top of the page. Building Instacart Meals
Building Instacart Meals  7 steps to get started with large-scale labeling
7 steps to get started with large-scale labeling 

Most Recent in How It's Made

How It's Made
One Model to Serve Them All: How Instacart deployed a single Deep Learning pCTR model for multiple surfaces with improved operations and performance along the way
Authors: Cheng Jia, Peng Qi, Joseph Haraldson, Adway Dhillon, Qiao Jiang, Sharath Rao Introduction Instacart Ads and Ranking Models At Instacart Ads, our focus lies in delivering the utmost relevance in advertisements to our customers, facilitating novel product discovery and enhancing…...
Dec 19, 2023
How It's Made
Monte Carlo, Puppetry and Laughter: The Unexpected Joys of Prompt Engineering
Author: Ben Bader The universe of the current Large Language Models (LLMs) engineering is electrifying, to say the least. The industry has been on fire with change since the launch of ChatGPT in November of…...
Dec 19, 2023
How It's Made
Unveiling the Core of Instacart’s Griffin 2.0: A Deep Dive into the Machine Learning Training Platform
Authors: Han Li, Sahil Khanna, Jocelyn De La Rosa, Moping Dou, Sharad Gupta, Chenyang Yu and Rajpal Paryani Background About a year ago, we introduced the first version of Griffin, Instacart’s first ML Platform, detailing its development and support for end-to-end ML in…...
Nov 22, 2023