How It's Made
Terraforming RDS — Part 1
The basics of Terraform and RDS.
At Instacart we are approaching a hundred PostgreSQL instances running in AWS RDS. They are all managed in Terraform. Using Terraform with RDS has caused a lot of pain over the years, but it has saved us even more pain.
In this series of posts I’ll cover:
- What RDS and Terraform are
- Why it can be painful to manage RDS with Terraform
- Why managing RDS with Terraform is totally worth it
Instacart, Terraform, and me
I’ve been working on the Infrastructure team at Instacart for two years; before that, I was a back-end developer for our orders team. The Infra team started using Terraform several months before I joined, and we made quite a few newbie mistakes. I started my work with the team and with Terraform by copying a lot of those mistakes 😅.
Two years later, I’ve learned a lot. Along with a few other members of the Infra team and several of our engineers, I’ve led the effort to clean up our Terraform and configure thousands of our AWS resources using Terraform, including dozens of RDS Postgres instances and their replicas.
In the last year, we’ve also been working on applying our Terraform configuration to multiple environments. This allows us to create development and staging environments that are as similar as possible to our production environment but also adds significantly to the complexity of our Terraform.
What is RDS?
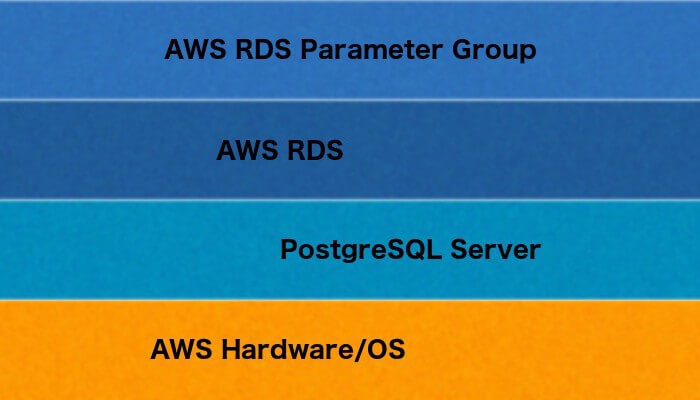
RDS is AWS’s Relational Database Service. They manage the hardware, the server installation, setup, and other administrative tasks such as version upgrades and backups. RDS is an abstraction layer — you don’t have direct access to the PostgreSQL server code, the logs, or the operating system. You can read more about this in the AWS documentation.

Parameter groups
AWS adds another abstraction layer in the form of parameter groups. PostgreSQL has many server configuration parameters. When managing your own server you can set these in the postgresql.conf file, on the command line at server startup, or using SQL. With an AWS-managed server, you set these values using a parameter group.
I’ll discuss parameter groups a bit more in another post; for now, it’s sufficient to know that this adds an additional layer of abstraction over your PostgreSQL server.
What is Terraform?
Terraform is a tool for building, changing, and versioning infrastructure. It allows you to treat your infrastructure as code. You define your infrastructure using HashiCorp’s HCL language, check these configurations into source control, and then update your resources by using Terraform to plan and apply the changes.
So, Terraform also acts as an abstraction layer over your infrastructure.
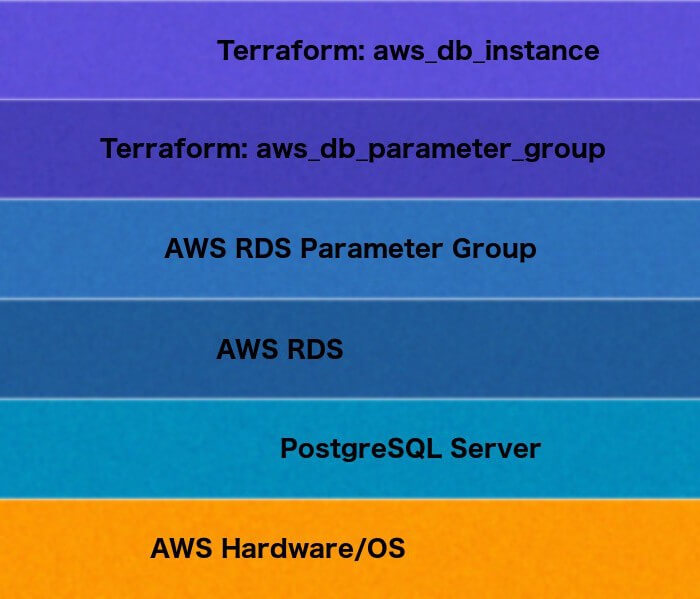
Terraform is not a very strong abstraction, as it makes use of different providers for different services. This also means that it is not agnostic — if you create a database using the AWS provider, you will not be able to simply change your provider to Google Cloud and then apply the same Terraform. However, once you have all of your resources configured through Terraform, you also have a well-organized description of your infrastructure, so you can “port” your infrastructure code to a different provider just as you might port your software to a different language.
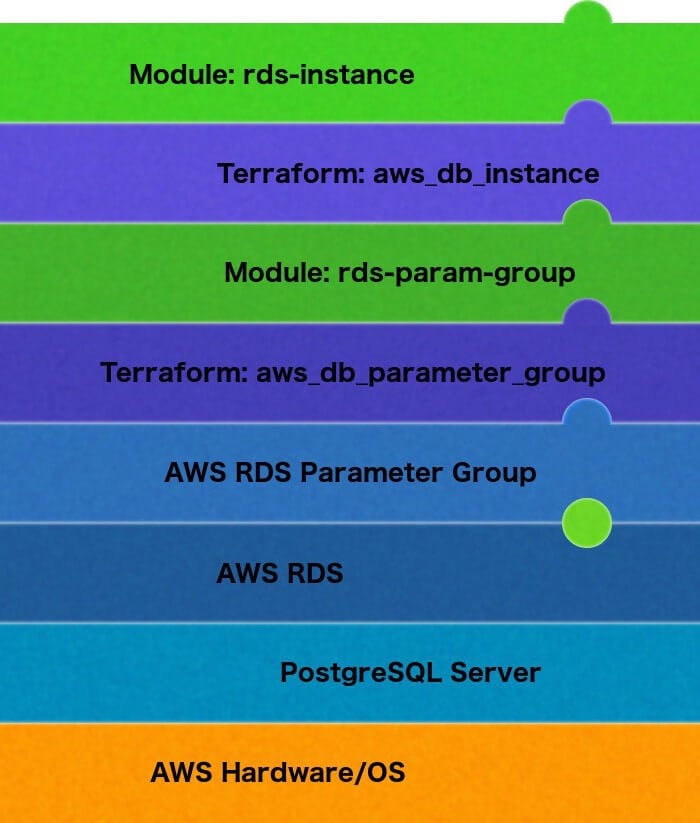
Terraform modules
As you can imagine, you will be configuring many instances of each type of resource, and so you will end up copying your code over and over. Further, you may want to create certain resources together such as a database instance, parameter group, and PGBouncer service. To support these kinds of reuse, Terraform allows you to create modules, which are reusable blocks of Terraform code with inputs and outputs, much like a function in software. I’ll cover more about modules in another post.
Modules add yet another layer of abstraction between you and your resources, and since modules can reference other modules, this layer can be as deep as you allow it to be.

Abstraction
Okay, I’ve mentioned abstraction half a dozen times now, so it’s probably important to my point… but isn’t abstraction supposed to be a good thing? It is supposed to help us manage complexity and insulate us from the uncomfortable details of implementation.

The Princess and the Pea
There’s an old fairy tale about a prince searching for a princess. The real princess is identified when she is given a bed piled with dozens of mattresses on top of a single pea. She tosses and turns all night because she can feel the pea through all the mattresses, which would insulate anyone else from the minor perturbation of the pea.
Imperfect abstractions act on your systems like the pea on the princess. They can cover up a detail that nonetheless can be quite painful. When you are working on a system with many layers of abstractions, it’s also hard to dig through all those layers to find the pea.
The final post of this series will be a case study of where we were bitten hard by one of these abstractions, but first I’ll go over some of the surprises we encountered as we worked on getting our RDS instances into Terraform and managing them for the last couple of years.
Terraform and RDS defaults
Using Terraform to create an RDS instance is very easy. Put the following in an HCL file, such as rds.tf:
resource "aws_db_instance" "muffy-test" {
allocated_storage = 100
db_subnet_group_name = "db-subnetgrp"
engine = "postgres"
engine_version = "11.5"
identifier = "muffy-test"
instance_class = "db.m5.large"
password = "password"
skip_final_snapshot = true
storage_encrypted = true
username = "postgres"
}
There are many more attributes you could specify, but this is enough to get started.
terraform plan
Now run terraform plan. The plan shows what Terraform will create in AWS. Notice all the values that you did not set in rds.tf that are being set or will be “known after apply”. These are supplied either by the Terraform provider (in italics) or by AWS RDS (plain text). The values you set in your HCL are bold.
An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: + create# aws_db_instance.muffy-test will be created + resource "aws_db_instance" "muffy-test" { + address = (known after apply) + allocated_storage = 100 + apply_immediately = (known after apply) + arn = (known after apply) + auto_minor_version_upgrade = true + availability_zone = (known after apply) + backup_retention_period = (known after apply) + backup_window = (known after apply) + ca_cert_identifier = (known after apply) + character_set_name = (known after apply) + copy_tags_to_snapshot = false + db_subnet_group_name = "db-subnetgrp" + endpoint = (known after apply) + engine = "postgres" + engine_version = "11.5" + hosted_zone_id = (known after apply) + id = (known after apply) + identifier = "muffy-test" + identifier_prefix = (known after apply) + instance_class = "db.r5.large" + kms_key_id = (known after apply) + license_model = (known after apply) + maintenance_window = (known after apply) + monitoring_interval = 0 + monitoring_role_arn = (known after apply) + multi_az = (known after apply) + name = (known after apply) + option_group_name = (known after apply) + parameter_group_name = (known after apply) + password = (sensitive value) + performance_insights_enabled = false + performance_insights_kms_key_id = (known after apply) + performance_insights_retention_period = (known after apply) + port = (known after apply) + publicly_accessible = false + replicas = (known after apply) + resource_id = (known after apply) + skip_final_snapshot = true + status = (known after apply) + storage_encrypted = true + storage_type = (known after apply) + timezone = (known after apply) + username = "postgres" + vpc_security_group_ids = (known after apply) }Plan: 1 to add, 0 to change, 0 to destroy.
Terraform apply
Now go ahead and apply the plan with terraform apply.
% terraform apply .terraform.output Acquiring state lock. This may take a few moments... aws_db_instance.muffy-test: Creating... aws_db_instance.muffy-test: Still creating... [10s elapsed] aws_db_instance.muffy-test: Still creating... [20s elapsed] aws_db_instance.muffy-test: Still creating... [30s elapsed] aws_db_instance.muffy-test: Still creating... [40s elapsed] [...] aws_db_instance.muffy-test: Still creating... [2m20s elapsed] aws_db_instance.muffy-test: Still creating... [2m30s elapsed] aws_db_instance.muffy-test: Creation complete after 2m39s [id=muffy-test]Apply complete! Resources: 1 added, 0 changed, 0 destroyed. Releasing state lock. This may take a few moments...
Creating this instance took just a few minutes, but most instances that we create at Instacart take 30–40 minutes. Watching the creation on the command line like this is much easier than frequently refreshing the AWS console in the browser.
Terraform state
When it shows you the results of the apply, Terraform doesn’t show you all the values that are actually set on your instance, so you’ll need to take a look at what was created either in the AWS console or by using terraform state show. Look at the output of show below and notice how many values were set for us by either the Terraform provider (italic) or RDS itself (plain text). Only the values in bold were explicitly set in our rds.tf file:
% terraform state show aws_db_instance.muffy-test
# aws_db_instance.muffy-test:
resource "aws_db_instance" "muffy-test" {
address = "muffy-test.....com"
allocated_storage = 100
arn = "arn:...:db:muffy-test"
auto_minor_version_upgrade = true
availability_zone = "us-east-1b"
backup_retention_period = 0
backup_window = "04:40-05:10"
ca_cert_identifier = "rds-ca-2019"
copy_tags_to_snapshot = false
db_subnet_group_name = "db-subnetgrp"
delete_automated_backups = true
deletion_protection = false
endpoint = "muffy-test...:5432"
engine = "postgres"
engine_version = "11.5"
hosted_zone_id = "Z2R2ITUGPM61AM"
iam_database_authentication_enabled = false
id = "muffy-test"
identifier = "muffy-test"
instance_class = "db.m5.large"
iops = 0
kms_key_id = "arn:...:key/..."
license_model = "postgresql-license"
maintenance_window = "sat:08:12-sat:08:42"
max_allocated_storage = 0
monitoring_interval = 0
multi_az = false
option_group_name = "default:postgres-11"
parameter_group_name = "default.postgres11"
password = (sensitive value)
performance_insights_enabled = false
performance_insights_retention_period = 0
port = 5432
publicly_accessible = false
replicas = []
resource_id = "db-EJHF7...W6VLWRE"
skip_final_snapshot = true
status = "available"
storage_encrypted = true
storage_type = "gp2"
username = "postgres"
vpc_security_group_ids = [
"sg-81f064e5",
]
}
Magic.
Applying changes

Some changes to an RDS instance can be applied while it is still running, while others may require a server restart. The aws_db_instance resource allows you to indicate whether or not to do a restart if needed by using the apply_immediately attribute. However, there is nothing in the documentation of the provider which tells you which changes will cause a restart and which will not.
The AWS provider docs do warn you that a server restart might cause “some downtime” — in our experience, a database restart can take several minutes, which doesn’t sound so bad until you think what that means to the overall system. Customers may not be able to place orders, they may not even be able to see our website at all, shoppers may not be able to get information about orders to fill, retailers may not be able to send us new catalog data.
So, just setting apply_immediately to true and going for it is not really an option. On the other hand, if you do not apply the changes immediately when DO they get applied? According to the documentation, “during the next maintenance window,” but what does that mean? Probably a time in the middle of the night when no one is watching, so what if something goes wrong with the changes? Applying database changes is something you want to carefully control, and the combination of RDS and Terraform makes that quite a bit harder.
You can, of course, dig into the AWS documentation to find out which changes can be applied without a server restart. However, suppose you do not read the docs carefully and you try to change the allocated storage in your rds.tf file, with apply_immediately set to false:
resource "aws_db_instance" "muffy-test" {
allocated_storage = 16000
apply_immediately = false
[...]
}
terraform plan
An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: ~ update in-placeTerraform will perform the following actions:# aws_db_instance.muffy-test will be updated in-place ~ resource "aws_db_instance" "muffy-test" { ~ allocated_storage = 100 -> 16000 + apply_immediately = false [...] }Plan: 0 to add, 1 to change, 0 to destroy.
terraform apply
aws_db_instance.muffy-test: Modifying... [id=muffy-test] ...muffy-test: Still modifying... [id=muffy-test, 10s elapsed] ...muffy-test: Still modifying... [id=muffy-test, 20s elapsed] ...muffy-test: Still modifying... [id=muffy-test, 30s elapsed] ...muffy-test: Modifications complete after 32s [id=muffy-test]Apply complete! Resources: 0 added, 1 changed, 0 destroyed.
Nothing here tells you that the changes have not in fact been applied, but if you look at your database in the AWS console, you will see that it is no larger than it was before.
apply_immediately
Set apply_immediately to true and plan again. Terraform will show the change to the value of apply_immediately, and it will also show that you have not yet actually updated the allocated storage.
terraform plan
An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: ~ update in-placeTerraform will perform the following actions:# aws_db_instance.muffy-test will be updated in-place ~ resource "aws_db_instance" "muffy-test" { ~ allocated_storage = 100 -> 16000 ~ apply_immediately = false -> true [...] }Plan: 0 to add, 1 to change, 0 to destroy.
terraform apply
aws_db_instance.muffy-test: Modifying... [id=muffy-test] ...muffy-test: Still modifying... [id=muffy-test, 10s elapsed] ...muffy-test: Still modifying... [id=muffy-test, 20s elapsed] ...muffy-test: Still modifying... [id=muffy-test, 30s elapsed] [...] ...muffy-test: Still modifying... [id=muffy-test, 26m1s elapsed] ...muffy-test: Still modifying... [id=muffy-test, 26m11s elapsed] ...muffy-test: Modifications complete after 26m14s [id=muffy-test]Apply complete! Resources: 0 added, 1 changed, 0 destroyed.
Note that this apply took a great deal longer than the one that did not actually change your db. Take a look in the AWS console and you will see that your space has been increased.
terraform plan
If you run terraform plan one more time, Terraform shows no differences:
% terraform plan -out=.terraform.output Refreshing Terraform state in-memory prior to plan... The refreshed state will be used to calculate this plan, but will not be persisted to local or remote state storage.aws_db_instance.muffy-test: Refreshing state... [id=muffy-test]--------------------------------------------------------------------No changes. Infrastructure is up-to-date.This means that Terraform did not detect any differences between your configuration and real physical resources that exist. As a result, no actions need to be performed.
Why Infrastructure as Code (IaC)?
Okay, so I said at the beginning that using Terraform with RDS is worthwhile. The biggest reason is that Infrastructure as Code (IaC) is a great idea, and Terraform is one of the best tools around for implementing it.
So why IaC?
It’s the hot new thing in DevOps
Okay, that’s not actually a good reason, but if all the smart experienced people in your field are doing something, it’s likely a good idea to follow them.
It’s a descriptive model for your environment
Without IaC, how do you describe your environment? Probably you make some pictures which will never be up to date, because things are always changing. IaC gives you the ability to write down what you want in your infrastructure and then create those resources directly from that description, so it always matches what is actually running.
It’s a development cycle for infrastructure
Since IaC is implemented with text files, it is easy to add source control and a release cycle to your infrastructure, giving you all the same benefits you get from putting your code in source control. I hope I don’t have to explain why source control is good 😬.
Terraform Pros
Reproducibility
We can and do use the same Terraform config to provision all of our production, staging, and development environments. We can also use it to tear down and recreate those environments.
Consistency
Using modules and also cut-and-paste (I know, but we all do it), you can apply your best practices to all resources or groups of resources of the same type much more easily than you can by using the AWS console.
Auditing
Since Terraform is “just code”, you can put it into a GitHub repo and get all the benefits of source control and code reviews.
Multiple providers
Terraform works with many providers, not just AWS, so you can manage most aspects of your infrastructure with it. For example, we use the DataDog and GitHub providers in addition to the AWS provider, and we have written our own provider to integrate with our service management and CI/CD system.
Terraform Cons
Too much abstraction
Terraform is quite powerful, but the layers of abstraction mean that you can easily do things that you do not intend to do, especially when one of the layers will“helpfully” do it for you.
Minimal control structures
While Terraform 0.12 has improved support for interpolation, conditional configuration, and mapping over collections, it is still not as full-featured as a programming language, which can lead to some very tortured-looking config that is hard to read.
Plan drift
Unless you completely lock down CLI and console changes, you can end up with unexpected differences in your plans due to changes made outside of Terraform. This makes it difficult for both the person updating the HCL and the reviewer, and can lead to unexpected reversions.
State management
I barely touched on Terraform state management here, but when you need to import existing resources or you decide to move config around, you have to modify the state that Terraform has stored. Modifying the state is a very manual (and tedious) process, as you have to import, move, or delete resources one by one.
Recommendations
Infrastructure as code
Do it. Absolutely. Having our resources configured in a source code repo has saved us an enormous amount of time both spinning up new environments and recovering from errors. It allows us to review infrastructure changes before actually making them, which has let us catch many issues before they go live. It can, of course, introduce other sources of error due to the layers of abstraction, but the net result is hugely positive.
Terraform
I like it. There are other options, but Terraform is supported by a very good company, HashiCorp, and has an excellent community and a wide range of well-maintained providers for all of our infrastructure.
AWS RDS
I like RDS too. Some of our engineers argue that we should self-host our Postgres instances, but as one of the people who is responsible for system configuration, updates, backups, and other maintenance work on our databases, I’m happy to have that taken off my plate.
Further reading
Subsequent posts will cover:
- Using parameter groups and Terraform modules
- That time an abstraction bit us really hard
Want to work on challenges like these? Surprise, Instacart is hiring! Check out our current openings.

Muffy Barkocy
Muffy Barkocy is a member of the Instacart team. To read more of Muffy Barkocy's posts, you can browse the company blog or search by keyword using the search bar at the top of the page. Building Instacart Meals
Building Instacart Meals  7 steps to get started with large-scale labeling
7 steps to get started with large-scale labeling 

Most Recent in How It's Made

How It's Made
One Model to Serve Them All: How Instacart deployed a single Deep Learning pCTR model for multiple surfaces with improved operations and performance along the way
Authors: Cheng Jia, Peng Qi, Joseph Haraldson, Adway Dhillon, Qiao Jiang, Sharath Rao Introduction Instacart Ads and Ranking Models At Instacart Ads, our focus lies in delivering the utmost relevance in advertisements to our customers, facilitating novel product discovery and enhancing…...
Dec 19, 2023
How It's Made
Monte Carlo, Puppetry and Laughter: The Unexpected Joys of Prompt Engineering
Author: Ben Bader The universe of the current Large Language Models (LLMs) engineering is electrifying, to say the least. The industry has been on fire with change since the launch of ChatGPT in November of…...
Dec 19, 2023
How It's Made
Unveiling the Core of Instacart’s Griffin 2.0: A Deep Dive into the Machine Learning Training Platform
Authors: Han Li, Sahil Khanna, Jocelyn De La Rosa, Moping Dou, Sharad Gupta, Chenyang Yu and Rajpal Paryani Background About a year ago, we introduced the first version of Griffin, Instacart’s first ML Platform, detailing its development and support for end-to-end ML in…...
Nov 22, 2023